16 dakikada okunabilir.
Model Bozunması: Veri Kayması ve Konsept Kayması
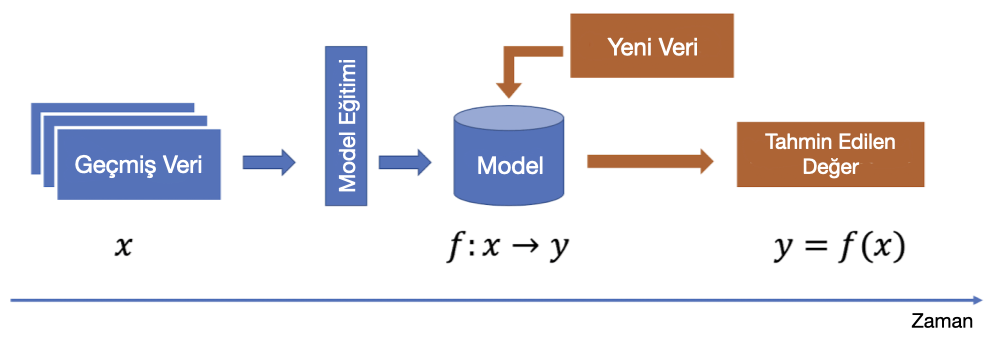
Tahmine dayalı modellemede (aşağıdaki şekilde gösterildiği gibi), geçmiş verilere dayalı olarak bir denetimli model eğitir ve ardından önceden görülmemiş verileri tahmin etmek için bu eğitilmiş modeli kullanırız. Bu süreçte, model, hedef değişken (target variable) ile girdi öznitelikleri (input features) arasındaki ilişkiyi öğrenir. Bu ilişki $y = f(x)$ gibi bir fonksiyon ile tanımlanabilir. Bu fonksiyona eşleme fonksiyonu (matching function) denir. Genellikle, bu eşlemenin statik (sabit) olduğu varsayılır; bu, geçmiş verilerden öğrenilen eşlemenin gelecekte yeni veriler üzerinde de geçerli olduğu ve girdi ve çıktı verileri arasındaki ilişkilerin değişmediği anlamına gelir.
Makine öğrenmesi modelleri genellikle bozuk, gecikmiş veya tamamlanmamış verilerle ilgilenir. Veri kalitesi genellikle doğruluk (accuracy), tamlık (completeness), tutarlılık (consistency), zamanlılık (timeliness), geçerlilik (validity) ve benzersizlik (uniqueness) gibi altı boyutla tanımlanır. Veri kalitesi sorunları, üretim ortamına dağıtan modellerin başarısızlıkların büyük bir bölümünü oluşturur.
Ancak, diyelim ki, herhangi bir veri problemiminiz bulunmamakta. Veri mühendisliği ekibiniz harika bir iş çıkarıyor, ve verileri aldığınız veri sahipleri ve veri üreticileri kasıtlı herhangi bir zarar yaratmıyor ve sisteminizde herhangi bir kesinti bulunmuyor. Bu, modelimizin güvende olduğu anlamına mı geliyor?
Ne yazık ki, bu durum gerçek hayatta gerçekleşmez. Verileriniz ne kadar doğru olsa da ve doğru kalmayı başarsa da, modelin kendisi bozulmaya başlayabilir.
Bunu milyonlarca kez duyduğunuzu biliyoruz ama bir kez daha söyleyeceğiz: Hiçbir şey sonsuza kadar sürmez. Sonsuza kadar genç kalamazsınız, telefonunuz zamanla yavaşlar ve makine öğrenmesi modelleri zamanla bozunur. Termodinamiğin ikinci yasasının dediği gibi, zamanla işler felakete doğru yönelir. Makine öğrenmesi dünyasında bu, bir modelin tahmin gücünün zamanla kötüleşebileceği anlamına gelir. Bu nedenle modelleri etkili bir şekilde izlemek (monitoring), makine öğrenimi servisinizin başarılı olması için çok önemlidir.
Model bozunması çok çeşitli sebepler nedeniyle gerçekleşebilir. Ancak, kolay anlaşılabilir bir örnek verelim. Bir e-ticaret (e-commerce) platformunun arka planında çalışan bir ürün öneri sistemi (product recommendation system) düşünün. COVID-19’dan önce eğitilmiş bir modelin, COVID-19 salgını sırasında toplanan veriler ile eşit derecede iyi çalışabileceğini düşünüyor musunuz? Bu tür öngörülemeyen durumlar nedeniyle kullanıcı davranışı çok değişmektedir. Kullanıcıların çoğu, artık pahalı ürünler satın almak yerine günlük temel malzemeleri satın almaya odaklanmıştır. Bu, kullanıcı davranışını tanımlayan verilerin tamamiyle değişti anlamına gelir. Buna ek olarak, bu tür bir durumda piyasada birçok ürün stokta kalmadığından, kullanıcılar için tamamen farklı bir alışveriş modeli gerçeklemeniz gerekmektedir.

Daha bilimsel açıklayacak olursak, oluşturduğunuz model, büyük ihtimalle, istatistiksel özellikleri değişmeyen statik (sabit) veriler kullanarak statik bir ortamda çalışmaktadır. Bu durumda, tahmin ettiğimiz veriler eğitim için kullanılan verilerle aynı dağılımdan geldiğinden modeliniz performansından hiçbir şey kaybetmemelidir. Peki, modeliniz, bazılarını kontrol edemediğimiz birçok değişkeni içeren dinamik ve sürekli değişen bir ortamda çalışıyorsa ne olur? Bu durumda modelin performansı da değişecektir. Çünkü oluşturduğunuz bu model yalnızca statik veri kümeleriyle değil, genellikle gerçek dünyadaki olaylarla etkileşime girecektir.
Diğer bir deyişle, zamanla, bir makine öğrenmesi modeli, model kayması (model drift) olarak bilinen bir kavramı yaşayarak, tahmin gücünü kaybetmeye başlar.
İşte bu blog yazısında, model kaymasını derinlemesine inceleyeceğiz ve en önemli iki nedenini keşfedeceğiz: konsept kayması (concept drift) ve veri kayması (data drift). Ayrıca, neden gerçekleştiklerine, etkilerine, onları nasıl tespit edebileceğimize ve nihayetinde etkilerinin nasıl üstesinden gelinebileceğine biraz ışık tutacağız.
Model Bozunması (Model Decay)
Literatürde, model bozunmasına (model decay), model kayması (model drift) veya model bayatlaması (model staleness) da denilmektedir.

Zamanla her şey değişir ve model performansı düşer. Nihai ölçü (measure), model kalite ölçütüdür (metric). Model kalite ölçütleri olarak, Doğruluk oranı (accuracy rate), ortalama hata oranı (mean error rate) veya tıklama oranı (click-through rate) gibi bazı Anahtar Performans Göstergeleri (Key Performance Indicator - KPI) kullanılabilir.
Hiç bir modelin sonsuza kadar yaşayamayacağı, ancak modellerin bozulma oranlarının (decay rate) değişebileceği de unutulmamalıdır. Bazı modeller güncelleme olmadan yıllarca çalışabilir. Örneğin, belirli bilgisayarlı görü veya doğal dil işleme modeli. Ya da izole, kararlı bir ortamda herhangi bir karar sistemi.
Model Bozunması, kelimenin tam anlamıyla modelin daha da kötüye gittiğini söyleyen bir terimdir. Ama elbette, belirli sebeplerden dolayı gerçekleşir. Veri kalitesi iyi olduğunda model bozunması gerçekleşiyorsa, iki olağan şüpheli vardır: veri kayması (data drift) veya konsept kayması (concept drift). Bazen her ikisi de aynı anda gerçekleşebilir.

Veri kayması (Data drift)
Veri kayması (data drift), öznitelik kayması (feature drift), ortak değişken kayması (covariate shift). Aslında aynı şeyi tanımlamak için birkaç isim bunlar. Bu tür kaymaya ortak değişken kayması denir, çünkü sorun ortak değişkenlerin (öznitelikler) dağılımındaki bir kaymadan kaynaklanır. Yani, $P(X)$’deki değişiklik, modelin girdi verisinin altındaki dağılımda yaşanan bir kaymadır. Ancak koşullu dağılım $P(y\mid x)$ değişmez.
Veri kayması iki sebeple gerçekleşir:
-
Örneklem seçim yanlılığı (Sample Selection Bias): Veri toplama veya etiketleme sürecinde, eğitim örneklerinin modellenecek popülasyondan eşit olmayan olasılıkla seçilmesine neden olan sistematik bir kusuru ifade eder. Veri kayması tamamiyle yanlış örnekleme sonucunda yaşanan yanlılık nedeniyle oluşuru. Bu durum, genellikle, statik ortamda üretilen modellerde yaşanan veri kaymasını kolaylıkla açıklayabilir. Veri bütünlüğü (data integrity), yaşam döngüsü boyunca verilerin güvenilirliğini ifade eder. Veri bütünlüğü sorunları olduğunda gerçekleşen bu tür veri kayması probleminde, bir araştırmacının bu problemin kaynağını detaylı araştırması ve hatalı veri mühendisliği adımını düzeltmesi gerekmektedir. Durum kod incelemeleri, hata ayıklama (debugging) vb. yoluyla çözülebilir.
-
Statik (durağan) olmayan ortam: Bu durum dış etkenler nedeniyle verilerde gerçek bir değişiklik olduğunda gerçekleşir. Herhangi bir makine öğrenmesi modeli geliştirmedeki temel varsayım, modeli eğitmek için kullanılan verilerin gerçek dünya verilerini (real-world data) taklit etmesidir. Ancak, model üretime dağıtıldıktan sonra bu varsayımı nasıl ileri sürebilirsiniz?
Bu tür veri kayması, üretim ortamında modelin karşılaştığı verilerin, modeli üretimde dağıtmadan önce test etmek ve doğrulamak için kullanılan verilerden farklı olması olarak tanımlanabilir. Verilerin kaymasına neden olabilecek birçok faktör vardır, bir anahtar faktör zaman boyutudur. Verilerin toplandığı ve modelin oluşturulduğu zaman ile modelin gerçek verilerle tahmin yapmak için kullanıldığı zaman arasında önemli bir boşluk bulunabilir. Bu boşluk, sorunun karmaşıklığına bağlı olarak haftalardan aylara veya yıllara kadar değişebilir.
Veri kayması, bağımsız değişkenlerin (independent variables veya features (öznitelikler)) özelliklerinin değiştiği bir model kayması türüdür. Değişkenlerin dağılımı anlamlı olarak farklıdır. Sonuç olarak, eğitilen model artık bu yeni verilerle ilgili değildir. Modeliniz yine de “eski” olana benzer veriler üzerinde iyi performans gösterecektir! Ancak pratik açıdan, yeni bir öznitelik uzayı (feature space) uğraştığımız için önemli ölçüde daha az kullanışlı hale gelecektir. Veri kayması bazen modeliniz için önemsiz olabilir. Ancak, kayma, en önemli değişkenleri etkilediğinde, dramatik bir şekilde gerçekleşecektir.
Veri kayması örnekleri, mevsimsellik nedeniyle verilerdeki değişiklikleri, tüketici tercihlerindeki değişiklikleri, yeni ürünlerin eklenmesini vb. içerir. Veri kaymasının en büyük örneği, daha önce de belirtildiği gibi, COVID-19 sağlık krizidir. Gerçekleşen pandemi nedeniyle, işletmelerin oluşturduğu ürün talebi ve müşteri davranışı ile ilgili makine öğrenmesi modelleri çok fazla etkilendi.
Makine öğrenmesi süreçlerinizi endüstrileştirmek istediğinizde, veri kaymasının gelişimini izlemek (monitoring) ve denetlemek (supervising) çok önemlidir.
Veri kaymasının ne kadar ciddi yaşandığı takip etmek ve gerekli uyarıları zamanında alabilmek için, bir MLOps (Makine Öğrenmesi Operasyonları - Machine Learning Operations) yaklaşımı uygulamak operasyonel kontrolü geri almanın mükemmel bir yoludur. Veri kaymasını tanımlamak için tekrarlanabilir bir süreç oluşturmak, kayma yüzdesinde (drift percentage) eşikler (threshold) tanımlamak, uygun önlemin alınması için proaktif uyarıyı yapılandırmak önemlidir. Örneğin, değişkenlerinin %50’sinden fazlasında istatistiksel olarak anlamlı bir değişiklik yaşanıyorsa, alarmları hemen çalıştırabilirsiniz. Ancak burada birçok nüans var. Kayma ne kadar büyük bir kaymadır? Değişkenlerimin sadece %10’unun kayması umurunuzda mı? Kayma’ya haftadan haftaya mı yoksa aydan aya mı bakmalıyım? Burada uygun eşiğin tanımlanması da çok önemlidir çünkü çok fazla yanlış alarm (false alarm) vermek istemeyiz ama aynı zamanda anlamlı değişikliklere tepki vermek isteriz. Şeytan ayrıntıda gizlidir. Bu sorulara verilecek cevap, büyük ölçüde modele, modelin kullanım durumuna, modelin yeniden eğitiminin ne kadar kolay (veya mümkün) olduğuna ve performans düşüşünün size ne kadara mal olduğuna bağlı olacaktır.
Veri kayması zamanında tespit edilmediğinde, tahminler yanlış gerçekleşecek, ve tahminlere dayalı olarak alınan iş kararları olumsuz etkilenebilecektir.
Veri kaymasını almak için modeli yeni veriler üzerinde eğitmemiz veya yeni oluşan segment için modeli yeniden oluşturmamız gerekiyor.
Veri kümesindeki kaymayı ölçmek için istatistiksel ölçümler kullanılabilir. Buradaki fikir, eğitim verilerinin dağılımının üretim verilerinin dağılımından farklı olup olmadığı hakkında bir sonuca varmak için veri kümeleriniz üzerinde çeşitli istatistiksel ölçütler kullanmaktır. Bu yaklaşımın önemli bir avantajı, özellikle finans ve bankacılık olmak üzere birçok sektörde halihazırda kullanılmakta olan bu metriklerin kullanıcı tarafından anlaşılmasıdır. Ayrıca, uygulanması daha basit olma avantajına da sahiptirler. Herhangi 2 popülasyon arasındaki farkı hesaplamak için kullanılan popüler istatistiksel yöntemlerden bazıları, Popülasyon Stabilite İndeksi (Population Stability Index), Kullback-Leiber Iraksaması (Kullback-Leiber Divergence), Jenson-Shannon Iraksaması (Jenson-Shannon Divergence), Kolmogorov-Smirnov Testi (basit bir hipotez testi), Wasserstein Ölçütü (Wasserstein Metric) veya Earth Mover Distance’tır. Bunlara ek olarak DDM (Kayma Algılama Yöntemi - Drift Detection Method) / EDDM (Erken Kayma Algılama Yöntemi - Early Drift Detection Method (EDDM)) gibi bazı istatistiksel süreç kontrol yöntemleri (statistical process control) kullanılabilir (Daha fazla bilgi için buraya ve buraya bakılabilir). Üçüncü bir yöntem ise zaman dağılımı tabanlı yöntemler (time distribution-based methods) kullanmaktır, örneğin, Adaptive Windowing (ADWIN). Çoğu yöntem, scikit-multiflow Python kütüphanesinde mevcuttur.
Etiket kayması (Label shift)
Ortak değişken kayması, özniteliklerin dağılımındaki değişikliklere odaklanırken, etiket kayması, sınıf değişkeninin (class variable) dağılımındaki değişikliklere odaklanır. Bu tür kayma türü, esasen ortak değişken (veri) kaymasının tersidir. Bunu düşünmenin sezgisel bir yolu, dengesiz bir veri kümesini düşünmek olabilir. Eğitim setimizdeki istenmeyen e-postaların (spam), istenmeyen posta olmayanlara (not-spam) oranı %50 ise, ancak gerçekte e-postalarımızın %10’u istenmeyen posta değilse, hedef etiket (target label) dağılımı değişmiştir.
Konsept kayması (Concept drift)
Konsept kayması, modelin öğrendiği örüntülerin (patterns) artık gerçekleşmediği zaman meydana gelir. $P(Y \mid X)$’deki değişiklik yaşanan bu kaymanın matematiksel gösterimidir. Konsept kayması, veri dağılımı (data distribution) veya sınıf dağılımı (class distribution) ile ilgili olmadığı, bunun yerine bu iki değişken arasındaki ilişki ile ilgili olduğu için veri kayması ve etiket kaymasından farklıdır.
Veri kaymasının tersine, bu kayma türünde, bağımsız değişkenlerin dağılımları aynı bile kalabilir. Bunun yerine, model girdileri ve çıktıları arasındaki ilişkiler değişmiştir. Özünde, konsept kayması tahmin etmeye çalıştığımız şeyin anlamının gelişmesidir veya değişmesidir. Yaşanan kaymanın ölçeğine bağlı olarak, bu, modeli daha az doğru ve hatta eski hale getirecektir. Örneğin, hileli (fraud) bir faaliyeti tespit etmeye yönelik bir modelde, neyin hileli olarak kabul edildiğine ilişkin tanımda bir değişiklik olabilir. Bu değişikliğin model tarafından uygulanması gerekir, ancak bir model bu değişikliği uygulanamazsa veya değişiklikle baş edemezse, model başarısız olur ve böyle bir soruna konsept kayması denir.
Literatüre göre konsept kayması, sınıf değişkeninin yani tahmin etmek istediğimiz hedefin istatistiksel özelliklerinin zaman içinde değiştiği olgudur. Bir model eğitildiğinde, bağımsız değişkenleri veya tahmin edicileri hedef değişkenlere eşleyen bir fonksiyon öğrenilir. Bu tahmin edicilerin veya hedefin hiçbirinin evrimleşmediği statik ve mükemmel bir ortamda, model ilk günkü gibi çalışmalıdır çünkü herhangi bir değişiklik yaşanmamıştır. Bununla birlikte, dinamik bir ortamda, yalnızca hedef değişkenin istatistiksel özellikleri değil, anlamı da değişir. Bu değişiklik gerçekleştiğinde, bulunan eşleme fonksiyonu (mapping function) artık yeni ortam için uygun değildir. Bu tür kaymalara en iyi örnek, yaşadığımız Covid-19 salgınıdır. Bu salgın nedeniyle, kullanıcıların alışveriş alışkanlıkları değiştiğinden, herhangi bir model doğru çalışmamamıştır, bu da tahminlerde çeşitli kusurlara ve dolayısıyla model bozulmasına yol açmıştır.

Konsept kayması farklı türlerde gerçekleşebilir.
Aşamalı konsept kayması (Gradual concept drift)
Aşamalı (gradual) veya artan (incremental) kayma, beklediğimiz şeydir. Dünya her geçen gün değişmekte, ve modeller yaşlanmaktadır. Bir modelin kalitesindeki düşüş, dış etkenlerdeki kademeli değişiklikleri takip etmektedir. Örneğin,
- Rakipler yeni ürünler piyasaya sürmeye başlayabilir. Böylelikle, tüketiciler daha fazla seçeneğe sahip olacak ve satın alma davranışları değişecektir. Tabii ki, satış öngörü (forecasting) modelleri de bundan etkilenecektir
- Makroekonomik koşullar değişebilir. Bazı borçlular kredilerini temerrüde düşürdükçe, kredi riski yeniden tanımlanır. Skorlama modellerinin bunu öğrenmesi gerekmektedir.
- Ekipmanın mekanik olarak aşınması. Aynı süreç parametreleri altında, örüntüler artık biraz daha farklıdır. Bu durum, imalatta kalite tahmin modellerini etkileyecektir.
Bu üç örnek için, yaşanacak bireysel değişikliklerin hiçbiri dramatik gerçekleşmeyecektir. Her biri yalnızca küçük bir segmenti (yani belirli dilimi) etkileyebilir. Ancak gerekli müdehale gerçekleşme, bu durum yığılmaya neden olacaktır.
Ani konsept kayması (Sudden or abrupt concept drift)
Dış değişiklikler daha ani veya şiddetli olabilir. Bunları gözden kaçırmak oldukça zordur. Yukarıda verdiğimiz gibi, bu duruma en mükemmel örnek COVID-19 salgınıdır. Bu salgın, neredeyse bir gecede, evde-kal politikası sebebiyle tüm hareketlilik ve alışveriş kalıplarını değiştirmiştir. Her türlü model bu durumdan etkilenmiştir. En “kararlı” modeller bile. Talep tahmin modelleri, yoga pantolonu satışlarının %350 artacağını (Stitch Fix’te olduğu gibi) veya sınırlar kapanırken çoğu uçuşun iptal edileceğini tahmin edememiştir. Bu durum sadece finansal modelleri değil, aynı zamanda sağlık sektöründe kullanılan modelleri de etkilemiştir. Röntgen görüntülerinde zatüreyi tanımaya çalışan bir modeliniz varken, bir gecede, anında yeni bir etiket (label) eklenmiştir.
Tabii ki bu tür ani değişiklikler her zaman bir pandemi veya borsa çöküşü gerektirmez. Daha sıradan bir olay akışında, aşağıdaki gibi şeyler yaşayabilirsiniz:
- Merkez bankası tarafından gerçekleştirilen faiz oranında değişiklik. Tüm finansal ve yatırım davranışları etkilenir ve modeller görünmeyen örüntülere uyum sağlayamaz.
- Üretim hattının teknik olarak yenilenmesi. Değiştirilen ekipmanın yeni arıza modlarına (veya bunların eksikliğine) sahip olması, arızaların bakım tahmini için kullanılan modelin işe yaramaz hale gelmesine neden olur.
- Uygulama arayüzünde gerçekleştirilen büyük bir güncelleme. Kullanıcının gerçekleştireceği her tıklama (click) ve yaşanacak dönüşümler (conversion) ile ilgili geçmiş veriler önemsiz hale gelir
Yinelenen veya Döngüsel konsept kayması (Recurring or cyclical concept drift)
Bazı araştırmacılar, tekrar eden değişiklikleri tanımlamak için “yinelenen kayma” terimini kullanmaktadır. Mevsimsellik (Seasonality) bilinen bir modelleme konseptidir. Gerçekten de hedef değişken üzerinde gerçekleşen geçici bir değişiklik gibi görünebilir (ki öyledir). Mevsimselliği işin içine alan modelleme yöntemleri vardır.
Yıl boyunca normal bir şekilde alışveriş yapan insanlar, Kara Cuma’da (Black Friday) olağandışı bir satın alma örüntüsü sergileyebilir. Resmi tatiller, perakende satışlardan üretim hatalarına kadar her şeyi etkileyebilir. Hafta sonu hareketlilik iş günlerinden farklıdır. Bunlar gibi bir çok örnek verilebilir. Sağlam bir modelimiz varsa, bu örüntülere kolay bir şekilde tepki vermelidir.
Her Kara Cuma, bir yıl önceki Kara Cuma’ya benzer. Sistem tasarımında döngüsel değişiklikleri (cyclical changes) ve özel olayları hesaba katabilir veya topluluk modelleri (ensemble models) oluşturabiliriz. böylelikle, “yinelenen konsept kayması” beklenecek ve kalite düşüşüne yol açmayacaktır. Model izleme açısından bu kayma türünün hiçbir önemi yoktur. Hafta sonları her hafta gerçekleşir ve bu durum için sistemimizde bir uyarı kurmaya ihtiyacımız yoktur. Tabii ki, yeni bir örüntü (kalıp) ile karşılaşana kadar.
Üretimdeki modelde gerçekleşen bu tam olarak olmayan kayma nasıl tedavi edilir?
Modelinize mevsimselliği öğretebilirsiniz. Üretime dağıtılan modeliniz ilk olarak bazı özel örüntüleri veya mevsimleri görürse, diğer benzer olayları örnek olarak kullanabilirsiniz. Örneğin, yeni bir resmi tatil gerçekleşiyorsa, bilinen bir tatil ile benzerlik olduğunu varsayabilirsiniz. Gerekirse, alan uzmanları (domain expertise), model çıktısının üzerine manuel son-işleme (post-processing) kuralları veya düzeltici katsayılar eklemeye yardımcı olabilir. Örneğin, belirli bir kategori için model çıktısını $\%X$ oranında değiştirebilir veya iş sürecinin zarar görmemesini sağlamak için minimum veya maksimum değerler belirleyebilirsiniz. Gerçek hayatta, DoorDash, talep tahmini gerçekleştiren modelinde, uzman bilgisini makine öğrenimi ile birleştirmektedir.
Dual Kayma (Dual Drift)
Model dinamik bir ortamda çalışır. İşler değişir. Veri kayması, konsept kayması veya her ikisini aynı anda yaşayabilirsiniz.
Model bozunmasından korunmak için neler yapılmalıdır?
Konsept kaymasından korunmak için yapılması gerekenler şunlardır:
- Gözlenen kaymanın gerçekten anlamlı olup olmadığına karar vermeniz gerekir. Tepki vermeniz gereken bir durum değilse, hiç bir şey yapmanıza gerek yoktur.
- Modelinizin herhangi bir kaymaya nasıl tepki verdiğinden memnun olabilirsiniz. Model tahminlerinde belirli bir sınıfın daha yaygın hale geldiğini gördüğünüzü varsayalım. Ancak gözlemlenen öznitelik kayması sizi rahatsız etmemektedir. Örneğin, onaylanmış kredi başvurularındaki artış, yüksek gelirli başvuru sahiplerindeki artışı takip etmektedir. Öznitelik ve tahmin kayması gibi görünebilir ancak beklediğiniz davranışla uyumludur. Tabii ki, her zaman bu şekilde olmaz. Gerçekçi eylemler gerçekleştirmeniz gerekebilir.
- Bazı makine öğrenmesi algoritmaları artımlı öğrenimine (incremental learning) izin verebilir. Model her seferinde bir örneği işlerken, algoritmanın anında güncellendiği çevrimiçi öğrenme kullanılabilir. Gerçek hayattaki uygulamaların çoğu akış verileri (streaming data) üzerinde çalışır ve çevrimiçi öğrenme (online learning), konsept kaymasını önlemenin en belirgin yoludur. Sonuç olarak, model her zaman veri dağılımındaki değişikliklere uyum sağlar.
- Model performansının belirli bir eşiğin altına düşmesi durumunda tetiklenebilecek şekilde, modeli periyodik olarak yeniden eğitebilirsiniz. Zor olan kısım, modelin yeniden eğitiminin gerekli olduğu anı tespit etmektir, ancak daha önce tartıştığımız gibi bunu yapmanın yolları vardır. Bu işlem maliyetli olabilir çünkü denetimli bir ortamda ek veri noktalarının yeniden etiketlenmesi gerekir. Bu nedenle, tüm veri kümesi üzerinde yeniden eğitim gerçekleştirmek yerine, tüm popülasyondan bir alt örneklem seçerek, modelinizi bu örneklem üzerinde yeniden eğitmeyi düşünebilirsiniz. Tabii ki, bu örnek seçimi (instance selection), örneklenen verilerin genel veri popülasyonunun özelliklerini temsil etmesi için, altta yatan verilerin dağılımı koruyarak gerçekleşmelidir. Burada önemli olan diğer bir kısım ise, yeni verilerin etiketlerinin mevcut olmasıdır. Çoğu zaman bu etiketlere sahipsinizdir ya da etiketleri bir yerlerden kolaylıkla bulabilirsiniz. Ancak bu sürecin maliyetli bir iş olduğunu unutmayın.
- Model performansının belirli bir eşiğin altına düşmesini beklemek zorunda değilsiniz. Yeni veriler eklendiğinde, modelinizi en son geçmiş verilere uyacak şekilde yeniden eğitebilirsiniz.
- Bazı makine öğrenimi modelleri güncellenebilir. Bu yöntem önceki yöntemlere göre daha verimlidir. Mevcut modeli başlangıç noktası olarak kabul edip en son verilerle güncelleyebiliriz (başlangıç kabul edilen modelin parametreleri (ağırlıkları) dondurulabilir. Örneğin, regresyon algoritmaları veya sinir ağları ).
- Bazı algoritmalar, girdi verilerini ağırlandırmanıza olanak tanır. Modelleri, daha güncel olan verilere daha fazla önem verecek şekilde yapılandırabiliriz.
- Eski modeli olduğu gibi bırakıp ve yeni veriler için yeni bir model oluşturup, bir topluluk öğrenme gerçekleştirebilirsiniz. Diğer bir deyişle, birden çok modelin birleştirildiği ve genel çıktının, bireysel model çıktılarının ağırlıklı bir ortalama olduğu model ağırlıklandırma ile topluluk öğrenmesi işe yarayabilir.
- Veriler, içerisindeki mevsimsel değişiklikler ortadan kaldırılabilecek şekilde biçimlendirilebilir. Örneğin, trend ve mevsimselliğe göre fark alınmış zaman serileri.
- Öznitelik bırakma (Feature dropping), konsept kaymasıyla başa çıkmanın başka bir yoludur. Bir seferde bir değişken (bir öznitelik) kullanılarak birden fazla model oluşturulur ve AUC-ROC yanıtının yeterli olmadığı durumlarda bu öznitelik (veya öznitelikler) analize dahil edilmez.
- Diyelim ki yukarıdaki çarelerin hiç biri işe yaramadı. İşte size radikal bir seçenek. Modeli hiç kullanmayın. Örneğin, uygulamanızda arka planında bir öneri sistemi çalışan bir kısım varsa, bu kısımı komple gizleyebilirsiniz.
Veri biliminde her zaman olduğu gibi, hiçbir garanti yoktur. Bazen en basit bir konsept kayması modeli tamamen bozabilir. Üretim hattında kalite tahmini üzerinde çalıştığınızı ve bu üretim hattının tamamen yenilendiğini hayal edin. Bu, model öğrenmeyi geçersiz kılar. Makine öğrenmesi sistemini yeniden kullanmak üzere yeterli eğitim verisini elde edene kadar, daha fazla yeni verinin toplanmasını beklemeniz gerekebilir.