29 dakikada okunabilir.
PyCaret ve Flask ile arkaplanında bir Makine Öğrenmesi Modeli bulunan bir web uygulaması oluşturmak
PyCaret, Python’da makine öğrenmesi iş akışlarını otomatikleştiren açık kaynaklı, az-kodlu bir makine öğrenmesi kütüphanesidir. Deneme döngüsünü üstel bir biçimde hızlandıran ve sizi daha üretken kılan uçtan uca bir makine öğrenmesi ve model yönetimi aracıdır. Diğer açık kaynaklı makine öğrenmesi kütüphaneleriyle karşılaştırıldığında, PyCaret, yüzlerce kod satırını yalnızca birkaç satıra düşürmek için kullanılabilen alternatif bir kütüphanedir. PyCaret esasen scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray ve birkaç tane daha makine öğrenmesi kütüphanesi ve yazılım çerçevesi etrafında bir Python sarmalayıcıdır.
Flask, Python’da API’ler oluşturmak için yaygın olarak kullanılan bir mikro web çerçevesidir. “Mikro”, tüm web uygulamanızın tek bir Python dosyasına sığması gerektiği (kesinlikle sığabilmesine rağmen) veya Flask’ın işlevsellikten yoksun olduğu anlamına gelmez. “Mikro web çerçevesi” ifadesindeki “mikro”, Flask’ın özünün basit ama genişletilebilir olduğu anlamına gelir.
Karmaşık uygulamalara ölçekleme yeteneği ile hızlı ve kolay bir şekilde başlamak için tasarlanmış basit ama güçlü bir Python kütüphanesidir. Flask, Web Server Gateway Interface (WSGI) araç takımına ve Jinja2 şablon motoruna (template engine) dayanmaktadır.
Bu eğiticide PyCaret kütüphanesini kullanarak Python’da makine öğrenimi iletim hattı (#pipeline) oluşturacak ve birden çok makine öğrenmesi modelini aynı anda eğiteceksiniz. Daha sonra, Flask kütüphanesini kullanarak, arka planında eğittiğiniz makine öğrenmesi modeli bulunan bir web uygulamasının kodunu yazacaksınız ve bu uygulamayı Heroku’da üretim ortamına dağıtacaksınız. Bir makine öğrenmesi modellerinin dağıtılması veya modellerin üretime alınması, modellinizi son kullanıcılar veya sistemler için kullanılabilir hale getirmek anlamına gelir.
Görevler
- İlk olarak PyCaret kütüphanesini kullanarak makine öğrenmesi modellerini eğiteceğiz (training) ve doğrulayacağız (validation). Daha sonra, dağıtım (deployment) için bir iletim hattı (pipeline) geliştireceğiz. Bu aşamada öğrenecekleriniz şunlardır:
- Veri Alma: PyCaret deposundan veri nasıl alınır.
- Ortamı Kurma: PyCaret’te bir regresyon deneyi nasıl kurulur ve regresyon modelleri oluşturmaya nasıl başlanır.
- Model Oluşturma: Model oluşturma, çapraz doğrulama gerçekleştirme ve regresyon ölçütlerini değerlendirme.
- Modele İnce Ayar Çekme: Bir regresyon modelinin hiperparametrelerinin otomatik olarak nasıl ayarlanacağı.
- Modelden Grafikler Elde Etme: Çeşitli grafikler kullanılarak model performansı nasıl analiz edilir.
- Modelden Tahminler Elde Etme: Yeni/ modelin görmediği veriler üzerinde nasıl tahmin yapılır.
- Modeli Kaydet / Geri Yükle: Daha sonra kullanılmak üzere bir model nasıl kaydedilir/yüklenir.
- Bağımsız değişkenler için bir girdi formuyla temel bir HTML ön ucu (front-end) oluşturacağız.
- Flask yazılım çerçevesini (framework) kullanarak web uygulamasının arka ucunu (back-end) oluşturacağız.
- Son olarak, oluşturduğumuz web uygulamasını Heroku’da dağıtacağız. Böylelikle, uygulama herkese açık hale gelecek ve web URL’si aracılığıyla erişilebilir olacaktır.
Görev 1 — Model Eğitimi ve Doğrulama
Model eğitimi (model training) ve model doğrulama (model validation), yerel makinenizde veya bulutta bir Entegre Geliştirme Ortamı (Integrated Development Environment - IDE) veya Jupyter Not Defteri kullanılarak gerçekleştirilir. Burada, kolaylık olması açısından, modeller Pycaret kütüphanesi kullanılarak elde edilecektir.
PyCaret’i daha önce kullanmadıysanız, PyCaret hakkında daha fazla bilgi edinmek için buraya tıklayınız veya web sitesindeki Başlangıç Eğitimlerine göz gezdiriniz.
Örnek olması açısından bu web uygulaması için bir regresyon modeli oluşturacağız. PyCaret’in regresyon modülü pycaret.regression (https://pycaret.org/regression1/), çeşitli algoritmalar ve teknikler kullanarak değerleri veya sonuçları tahmin etmek için kullanılan denetimli bir makine öğrenme modülüdür. 25’ten fazla algoritma ve modellerin performansını analiz etmek için 10’dan fazla grafik çizimi gerçekleştirir. Topluluk öğrenme (ensemble learning) ve hiperparametre ayarlama (hyperparameter tuning) gibi bir çok yöntem için PyCaret tek adresiniz olabilir.
Veri
Bu eğiticide, PyCaret’in veri kümesi deposundaki diamond veri kümesini kullanacağız. Bu veri kümesinde $6000$ gözlem bulunmaktadır. Her sütunun kısa açıklamaları aşağıdaki gibidir:
Carat Weight: Elmasın metrik karat cinsinden ağırlığı. Bir karat 0,2 grama eşittir, kabaca bir ataşla aynı ağırlıktadır.Cut: Elmasın kesimini gösteren beş değerden biri (Signature-Ideal, Ideal, Very Good, Good, Fair)Color: Elmasın rengini belirten altı değerden biri (D, E, F — Colorless, G, H, I — Near-colorless)Clarity: Elmasın berraklığını gösteren yedi değerden biri (F — Flawless, IF — Internally Flawless, VVS1 or VVS2 — Very, Very Slightly Included, or VS1 or VS2 — Very Slightly Included, SI1 — Slightly Included)Polish: Elmasın cilasını gösteren dört değerden biri (ID — Ideal, EX — Excellent, VG — Very Good, G — Good)Symmetry: Elmasın simetrisini gösteren dört değerden biri(ID — Ideal, EX — Excellent, VG — Very Good, G — Good)Report: İki değerden biri “AGSL” veya “GIA”, hangi derecelendirme kuruluşunun elmas kalitelerinin niteliklerini bildirdiğini gösterirPrice: Elmasın dolar cinsinden değeri (fiyatı)
İlk olarak gerekli tüm kütüphaneleri Python ortamına içe aktaralım:
import numpy as np
from pycaret.datasets import get_data
from pycaret.regression import *
from sklearn.model_selection import train_test_split
Daha sonra PyCaret kütüphanesindeki veri kümesine çağıralım:
dataset = get_data('diamond')
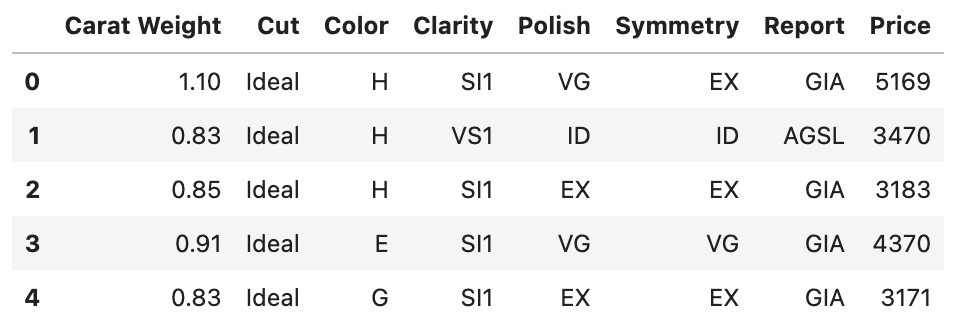
Veri kümesindeki değişkenlerin veri tiplerine bakalım:
dataset.dtypes
# Carat Weight float64
# Cut object
# Color object
# Clarity object
# Polish object
# Symmetry object
# Report object
# Price int64
# dtype: object
Veri kümesinin şeklini kontrol edelim:
dataset.shape
# (6000, 8)
Veri kümesinde kayıp gözlem olup olmadığını kontrol edelim:
dataset.isnull().sum()
# Carat Weight 0
# Cut 0
# Color 0
# Clarity 0
# Polish 0
# Symmetry 0
# Report 0
# Price 0
# dtype: int64
Burada Price değişkeni oluşturacağımız regresyon modeli için bağımlı değişken olacaktır.
Daha sonra, veri kümesindeki nümerik (sayısal) ve kategorik değişkenlerin isimlerini ayrı değişkenlere kaydedelim:
num_features = dataset.drop(['Price'], axis = 1).select_dtypes(include = 'number').columns
num_features
# Index(['Carat Weight'], dtype='object')
cat_features = dataset.select_dtypes(include = 'object').columns
cat_features
# Index(['Cut', 'Color', 'Clarity', 'Polish', 'Symmetry', 'Report'], dtype='object')
PyCaret’te Ortamı Ayarlama
setupfonksiyonu, ortamı PyCaret’te başlatır ve verileri modelleme ve dağıtım için hazırlamak için dönüştürme (transformation) iletim hattını (pipeline) oluşturur. pycaret’te başka bir fonksiyon yürütülmeden önce setup çağrılmalıdır. İki zorunlu parametre alır: bir pandas DataFrame ve hedef sütunun (bağımsız değişkeninin) adı. Diğer tüm parametreler isteğe bağlıdır ve ön işleme hattını özelleştirmek için kullanılır
s = setup(data = dataset,
target = 'Price',
train_size = 0.7,
categorical_features = list(cat_features),
numeric_features = list(num_features),
normalize = True,
normalize_method = 'minmax',
handle_unknown_categorical = True,
unknown_categorical_method = 'most_frequent',
session_id=42,
fold_strategy= 'kfold',
fold = 10)
Kurulum başarıyla yürütüldüğünde, birkaç önemli bilgi parçasını içeren bilgi ızgarasını görüntüler. Bilgilerin çoğu, kurulum yürütüldüğünde oluşturulan ön işleme hattı ile ilgilidir. Bu özelliklerin çoğu, bu eğiticinin amaçları için kapsam dışındadır. Ancak bu aşamada dikkat edilmesi gereken birkaç önemli nokta şunlardır:
session_id: Daha sonra gerçekleştirilebilecek olan tekrarlanabilirlik (reproducibility) için tüm fonksiyonlarda tohum (seed) olarak dağıtılan sözde rastgele bir sayı. Hiçbirsession_iddeğeri gönderilmezse, tüm fonksiyonlara dağıtılan rastgele bir sayı otomatik olarak oluşturulur. Bu deneyde,session_iddaha sonra tekrarlanabilirlik için42olarak ayarlanmıştır.Target: Bağımsız değişken sütununun ismini belirtir. Bu deney içinPricedeğişkeni hedef değişkendir.Original Data: Veri kümesinin orijinal şeklini görüntüler. Bu deney için kullanılacak veri kümesinin şekli (6000, 8)’dir. Yani, 6000 gözlen ve hedef sütun dahil 8 öznitelik (bağımsız değişken) anlamına gelir.Missing Values: Orijinal verilerde kayıp gözlemler olduğunda, buTrueolarak görünecektir. Bu deney için veri kümesinde kayıp gözlem yoktur.setupfonksiyonunnumeric_imputationvecategorical_imputationgibi iki farklı argümanı vardır. Bu argümanlar sırasıyla nümerik (sayısal) ve kategorik değişkenler için ayrı ayrı kayıp gözlem imputasyonu (missing value imputation) gerçekleştirir. Kategorik özniteliklerde kayıp gözlemler bulunursa, bu gözlemler sabit bir'not_available'(bulunamadı) değeriyle impute edilir. Mevcut diğer seçenek, eğitim veri setinde en sık görülen değeri kullanarak kayıp gözlemi impute eden'mod'dur. Benzer şekilde, sayısal özelliklerde kayıp gözlemler bulunursa, bu gözlemler öznitleiğin (değişkenin) ortalama ('mean') değeriyle hesaplanır. Mevcut diğer seçenek, eğitim veri kümesindeki medyan değeri kullanarak kayıp gözlemi impute eden'median'seçeneğidir.Numeric Features: Veri kümesindeki nümerik değişkenlerin (özniteliklerin) sayısını verir. Normalde Pycaret kütüphanesini kullandığında,setupfonksiyon veri setindeki değişkenlerin tiplerini otomatik olarak çıkaracaktır (inferred). Ancak, bensetupfonksiyonunu tanımlarken, nümerik değişkenlerin isimlerini fonksiyona besledim. Bunun nedeni, bazen çıkarsanan veri tipleri doğru olmamaktadır. Çıkarsanan türün üzerine yazmak içincategorical_featuresargümanı kullanılabilirCategorical Features: Veri kümesindeki kategorik değişkenlerin (özniteliklerin) sayısını verir. Normalde Pycaret kütüphanesini kullandığında,setupfonksiyon veri setindeki değişkenlerin türünü otomatik olarak çıkaracaktır. Ancak, bensetupfonksiyonunu tanımlarken, kategorik değişkenlerin isimlerini fonksiyona besledim. Bunun nedeni, bazen çıkarsanan veri tipleri doğru olmamaktadır. Çıkarsanan türün üzerine yazmak içinnumeric_featuresargümanı kullanılabilirOrdinal Features: Veriler sıralı özellikler içerdiğinde,setupfonksiyonun argümanlarından biri olanordinal_featuresparametresi kullanılarak farklı şekilde kodlanmaları gerekir. Kullandığımız veri, ‘düşük (low)’, ‘orta (medium)’, ‘yüksek (high)’ gibi değerlere sahip bir kategorik değişkene sahipse,düşük < orta < yüksekolduğu bilinmektedir. o zamanordinal_features = {'column_name' : ['low', 'medium', 'high']}. Liste sırası, en düşükten en yükseğe doğru artan sırada olmalıdır. Elimizdeki veri setinde, ordinal bir kategorik bir değişken bulunmadığı için bu argümana herhangi bir değer atamadık.train_size: Eğitim setinin boyutu. Varsayılan olarak, verilerin $\%70$’i eğitim ve doğrulama için kullanılacaktır. Kalan veriler bir test / hold-out kümesi için kullanılacaktır.Transformed Train Set: Dönüştürülen eğitim setinin şeklini görüntüler. (6000, 8) şekline sahip orijinal veri kümesinin, dönüştürülmüş eğitim kümesinin şekli (4199, 28)’dir. Kategorik kodlama (categorical encoding) nedeniyle özellik sayısı 8’den 28’e yükseldiTransformed Test Set: Dönüştürülmüş test/hold-out kümesinin şeklini görüntüler. Test/hold-out kümesinde 1801 örnek bulunmaktadır. Bu bölme, kurulumdatrain_sizeparametresi kullanılarak değiştirilebilen 70/30 varsayılan değerine dayanmaktadır.normalize:Trueolarak ayarlandığında, öznitelik uzayı (feature space)normalized_methodparametresi kullanılarak ölçeklenir.normalize_method:: Normalleştirme için kullanılacak yöntemi tanımlar. Varsayılan olarak, normalize etme yöntemi'zscore'olarak ayarlanmıştır. Bu örnek için Min-Max Ölçekleme kullanmak istediğimden'minmax'değerini bu argümana atadım.handle_unknown_categorical:Trueolarak ayarlandığında, yeni (new) / modelin görmediği (unseen) verilerdeki bilinmeyen kategorik seviyeler, eğitim veri kümesinden öğrenildiği gibi en sık (the most frequent) veya en az sık (least_frequent) görülen seviye ile değiştirilir. Hangi yöntemin kullanılacağıunknown_categorical_methodparametresi altında tanımlanır.unknown_categorical_method: modelin görmediği (unseen) verilerdeki bilinmeyen kategorik seviyeleri değiştirmek için kullanılan yöntemdir. Yöntem,"least_frequent"veya"most_frequent"olarak ayarlanabilir.- Bunlara ek olarak, model eğitimi sırasında kullanılacak çapraz doğrulama yöntemi
fold_strategyile, ve kat (fold) sayısıfoldargümanı ile seçilir.
Dönüştürülmüş (transformed) eğitim ve test veri kümelerine erişmek için get_config fonksiyonunu kullanarak erişebilirsiniz:
help(get_config)
# Help on function get_config in module pycaret.regression:
#
# get_config(variable: str)
# This function retrieves the global variables created when initializing the
# ``setup`` function. Following variables are accessible:
#
# - X: Transformed dataset (X)
# - y: Transformed dataset (y)
# - X_train: Transformed train dataset (X)
# - X_test: Transformed test/holdout dataset (X)
# - y_train: Transformed train dataset (y)
# - y_test: Transformed test/holdout dataset (y)
# - seed: random state set through session_id
# - prep_pipe: Transformation pipeline
# - fold_shuffle_param: shuffle parameter used in Kfolds
# - n_jobs_param: n_jobs parameter used in model training
# - html_param: html_param configured through setup
# - create_model_container: results grid storage container
# - master_model_container: model storage container
# - display_container: results display container
# - exp_name_log: Name of experiment
# - logging_param: log_experiment param
# - log_plots_param: log_plots param
# - USI: Unique session ID parameter
# - fix_imbalance_param: fix_imbalance param
# - fix_imbalance_method_param: fix_imbalance_method param
# - data_before_preprocess: data before preprocessing
# - target_param: name of target variable
# - gpu_param: use_gpu param configured through setup
# - fold_generator: CV splitter configured in fold_strategy
# - fold_param: fold params defined in the setup
# - fold_groups_param: fold groups defined in the setup
# - stratify_param: stratify parameter defined in the setup
# - transform_target_param: transform_target_param in setup
# - transform_target_method_param: transform_target_method_param in setup
#
#
# Example
# -------
# >>> from pycaret.datasets import get_data
# >>> boston = get_data('boston')
# >>> from pycaret.regression import *
# >>> exp_name = setup(data = boston, target = 'medv')
# >>> X_train = get_config('X_train')
#
#
# Returns:
# Global variable
get_config('X_train')

get_config('X_test')
Tüm Modelleri Karşılaştırma
Artık ortamımız tamamen işlevseldir. Kurulum tamamlandıktan sonra modelleme için önerilen başlangıç noktası, performansı değerlendirmek için tüm modelleri karşılaştırmaktır (ne tür bir modele ihtiyacınız olduğunu tam olarak bilmiyorsanız, ki genellikle durum böyle değildir). compare_models fonksiyonu, model kitaplığındaki tüm modelleri eğitir ve bunları metrik değerlendirme için k-katlı çapraz doğrulama kullanarak skorlar.
Sihirin gerçekleştiği yer burasıdır. Sadece tek bir kod satırı ile eğitim setinizi PyCaret’teki mevcut tüm modellerde çalıştırabilirsiniz. Mevcut modelleri aşağıdaki kodu yazarak görüntüleyebilirsiniz:
models()
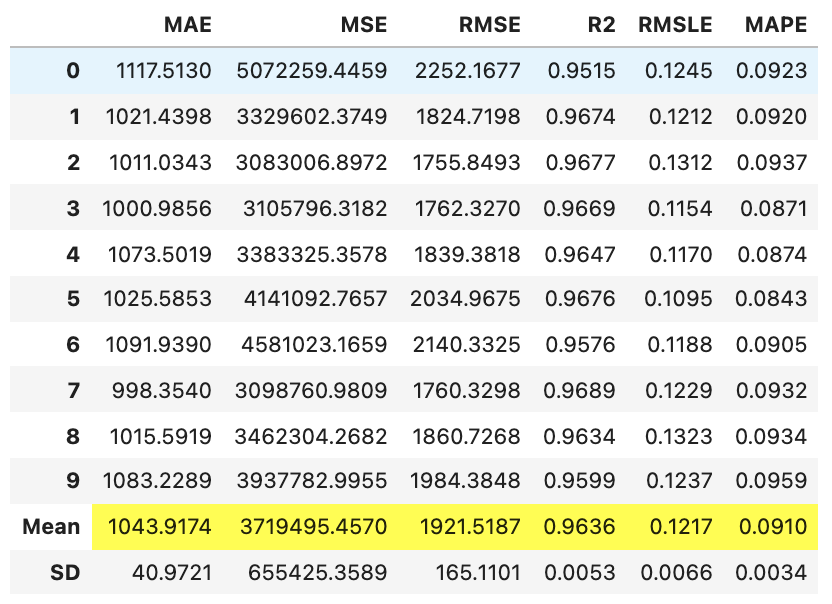
Şimdi tüm modelleri eğitiyoruz ve belirtme katsayısına (coefficient of determination - $R^2$) göre en iyisini seçiyoruz. Burada compare_models fonksiyonunu kullanırız. Bu fonksiyon, model kitaplığındaki tüm modelleri eğitir ve bunları metrik değerlendirme için k-katlı çapraz doğrulama (k-fold cross validation) kullanarak skorlar. Çıktı, her modelin eğitimi boyunca geçen süreyle birlikte katlar (folds) (varsayılan olarak 10) boyunca ortalama MAE, MSE, RMSE, R2, RMSLE ve MAPE’yi gösteren bir skorlama tablosu yazdırır. Ortalama Mutlak Hata (Mean Absolute Error - MAE), Ortalama Kare Hata (Mean Squared Error - MSE), Kök Ortalama Kare Hata (Root Mean Squared Error - RMSE), Belirtme Katsayısı (Coefficient of Determination - R2), Kök Ortalama Kare Logaritmik Hata (Root Mean Squared Logaritmic Error - RMSLE) ve Ortalama Mutlak Yüzde Hata (Mean Absolute Percentage Error - MAPE), kullanılan değerlendirme ölçütleridir. compare_models() fonksiyonunun sort argümanı ile hangi değerlendir ölçütüne göre modellerin sıralanacağını seçebilirsiniz.
best = compare_models(fold = 10, cross_validation = True, sort = 'R2', round=4, n_select = 1)
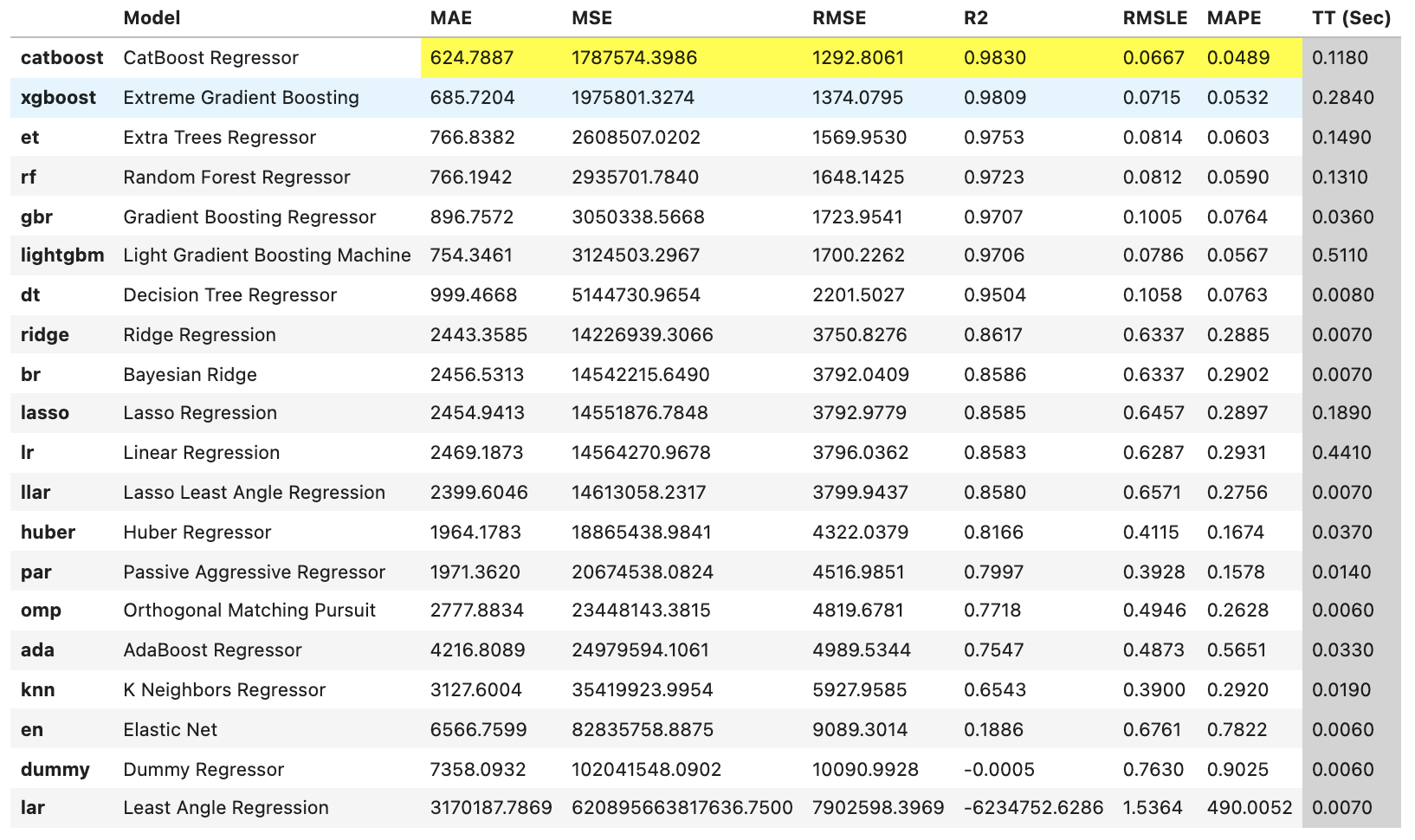
Bir satır kod ve çapraz doğrulama kullanarak 20’den fazla modeli eğittik ve değerlendirdik. Yukarıda yazdırılan skor tablosunda, yalnızca karşılaştırma amacıyla en yüksek performans gösteren metriği vurgular. Tablo sort = 'R2' R2 kullanılarak sıralanır (büyükten küçüğe). Not: compare_models skor tablosunda yazdırılan metrikler, tüm çapraz doğrulama katlarında elde edilen ölçütlerin ortalamasıdır.
Kolaylıkla anlaşılacağı üzere, burada en iyi model CatBoost algoritmasıdır ve diğer regresyon yöntemlerine göre en yüksek belirtme katsayısını ($\%98$) ve en düşük hata ölçütlerini vermiştir.
Bu model, best isimli nesneye kaydedilmiştir. Elde edilen modelin hiperparametrelerini bu nesnenin .get_all_params() niteliği ile ulaşılabilir.
best.get_all_params()
# {'nan_mode': 'Min',
# 'eval_metric': 'RMSE',
# 'iterations': 1000,
# 'sampling_frequency': 'PerTree',
# 'leaf_estimation_method': 'Newton',
# 'grow_policy': 'SymmetricTree',
# 'penalties_coefficient': 1,
# 'boosting_type': 'Plain',
# 'model_shrink_mode': 'Constant',
# 'feature_border_type': 'GreedyLogSum',
# 'bayesian_matrix_reg': 0.10000000149011612,
# 'force_unit_auto_pair_weights': False,
# 'l2_leaf_reg': 3,
# 'random_strength': 1,
# 'rsm': 1,
# 'boost_from_average': True,
# 'model_size_reg': 0.5,
# 'pool_metainfo_options': {'tags': {}},
# 'subsample': 0.800000011920929,
# 'use_best_model': False,
# 'random_seed': 42,
# 'depth': 6,
# 'posterior_sampling': False,
# 'border_count': 254,
# 'classes_count': 0,
# 'auto_class_weights': 'None',
# 'sparse_features_conflict_fraction': 0,
# 'leaf_estimation_backtracking': 'AnyImprovement',
# 'best_model_min_trees': 1,
# 'model_shrink_rate': 0,
# 'min_data_in_leaf': 1,
# 'loss_function': 'RMSE',
# 'learning_rate': 0.051360998302698135,
# 'score_function': 'Cosine',
# 'task_type': 'CPU',
# 'leaf_estimation_iterations': 1,
# 'bootstrap_type': 'MVS',
# 'max_leaves': 64}
Bir modele ince-ayar çekme
create_model fonksiyonu kullanılarak bir model oluşturulduğunda, modeli eğitmek için varsayılan hiperparametreleri kullanır. Hiperparametreleri ayarlamak için tune_model fonksiyonu kullanılır. Bu fonksiyon, önceden tanımlanmış bir arama alanında RandomGridSearch (Rastgele Izgara Arama) kullanarak bir modelin hiperparametrelerini otomatik olarak ayarlar. Çıktı, MAE, MSE, RMSE, R2, RMSLE ve MAPE’yi katlar (folds) boyunca gösteren bir skor tablosu yazdırır.
tuned_catboost = tune_model(estimator = best, fold = 10, search_library = 'scikit-learn', search_algorithm = 'random')
Kolaylıkla anlaşılacağı üzere, catboost algoritmasına 10-katlı çapraz doğrulama kullanılarak hiperparametre ayarlaması yapılmıştır.
Bu foksiyonun çok çeşitli argümanı var. İlk olarak, arama kütüphanesi seçilebilir. Pycaret şimdilik, Scikit-Learn, Scikit-Optimize, Tune-Sklearn, ve Optuna paketlerini desteklemektedir. Hiperparametre ayarlama için kullanılacak yöntem de search_library argümanı ile seçilen Python kütüphanesine göre yapılır. Bu kütüphaneler çok çeşitli arama yöntemlerini desteklemektedir, örneğin, Rastgele Arama (Random Search), Izgara Arama (Grid Search), Bayesci Arama (Bayesian Search) ve Ağaç yapılı Parzen Tahmincisi Araması (Tree-structured Parzen Estimator Search) gibi. Burada ben kullanılacak yöntem olarak Scikit-Learn kütüphanesindek, rastgele aramayı tercih ettim.
İşlem tamamlandıktan sonra en iyi hiperparametreler get_all_params() niteliği ile elde edilir.
tuned_catboost.get_all_params()
# {'nan_mode': 'Min',
# 'eval_metric': 'RMSE',
# 'iterations': 130,
# 'sampling_frequency': 'PerTree',
# 'leaf_estimation_method': 'Newton',
# 'grow_policy': 'SymmetricTree',
# 'penalties_coefficient': 1,
# 'boosting_type': 'Plain',
# 'model_shrink_mode': 'Constant',
# 'feature_border_type': 'GreedyLogSum',
# 'bayesian_matrix_reg': 0.10000000149011612,
# 'force_unit_auto_pair_weights': False,
# 'l2_leaf_reg': 4,
# 'random_strength': 0,
# 'rsm': 1,
# 'boost_from_average': True,
# 'model_size_reg': 0.5,
# 'pool_metainfo_options': {'tags': {}},
# 'subsample': 0.800000011920929,
# 'use_best_model': False,
# 'random_seed': 42,
# 'depth': 2,
# 'posterior_sampling': False,
# 'border_count': 254,
# 'classes_count': 0,
# 'auto_class_weights': 'None',
# 'sparse_features_conflict_fraction': 0,
# 'leaf_estimation_backtracking': 'AnyImprovement',
# 'best_model_min_trees': 1,
# 'model_shrink_rate': 0,
# 'min_data_in_leaf': 1,
# 'loss_function': 'RMSE',
# 'learning_rate': 0.5,
# 'score_function': 'Cosine',
# 'task_type': 'CPU',
# 'leaf_estimation_iterations': 1,
# 'bootstrap_type': 'MVS',
# 'max_leaves': 4}
Özelleştirilmiş arama ızgarasını kullanmak için tune_model fonksiyonunda custom_grid argümanına değer gönderebilirsiniz:
catboost_params = {'num_leaves': np.arange(10,200,10),
'max_depth': [int(x) for x in np.linspace(10, 16, num = 11)],
'learning_rate': np.arange(0.1,1,0.1)
}
tuned_catboost = tune_model(estimator = best, custom_grid = catboost_params, fold = 10, search_library = 'scikit-learn', search_algorithm = 'random')
Modelinizi üretim ortamına dağıtmak için en iyi modeli sonlandırırken göz önünde bulundurmanız gereken tek kriter ölçütler değildir. Göz önünde bulundurulması gereken diğer faktörler arasında eğitim süresi, k-katların standart sapması vb. bulunur. Şimdilik, tuned_catboost değişkeninde depolanan Catboost algoritmasını bu eğiticinin geri kalanı için en iyi modelimiz olarak ele alalım.
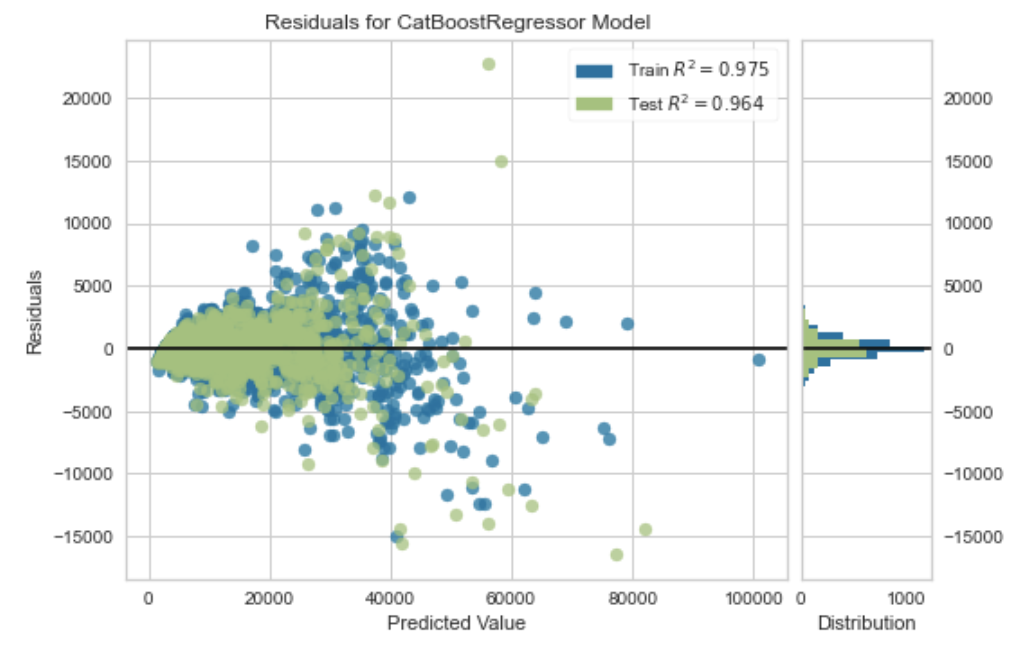
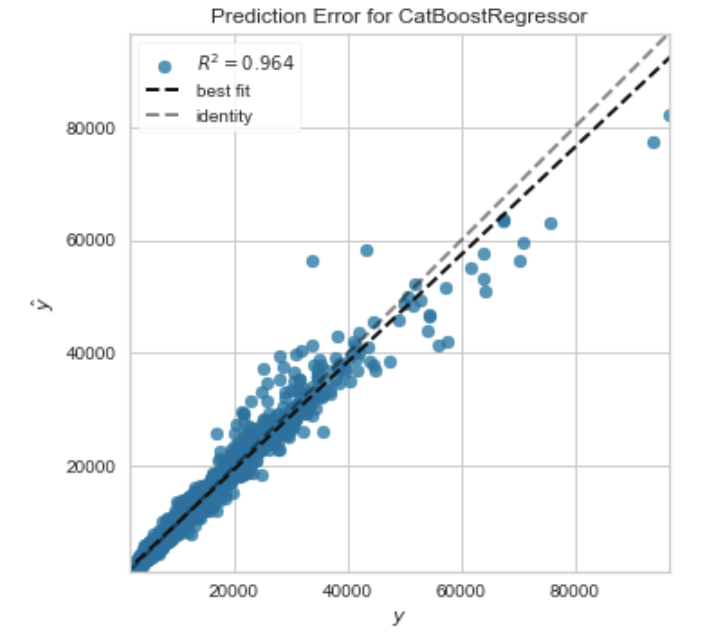
Model sonlandırılmadan önce, plot_model fonksiyonu, Artık Grafiği (Residuals Plot), Tahmin Hatası (Prediction Error), Öznitelik Önemi (Feature Importance) vb. gibi farklı yönlerdeki performansı analiz etmek için kullanılabilir. Bu fonksiyon, eğitilmiş bir model nesnesi alır ve test / hold-out kümesine dayalı bir grafik döndürür.
plot_model(estimator = tuned_catboost, plot = 'residuals')
plot_model(estimator = tuned_catboost, plot = 'error')
plot_model(estimator = tuned_catboost, plot='feature')

Modelinizin performansını analiz etmenin başka bir yolu, mevcut tüm grafikler için bir kullanıcı ara yüzü görüntüleyen evaluate_model fonksiyonunu kullanmaktır. Bu fonksiyon dahili olarak plot_model fonksiyonunu kullanır.
evaluate_model(tuned_catboost)
Test kümesindeki gözlemleri tahmin etme
Modeli sonlandırmadan önce, test / hold-out kümesini tahmin ederek ve değerlendirme metriklerini gözden geçirerek son bir kontrol yapılması tavsiye edilir. setup fonksiyonu ile verilerin %30’unun (1801 gözlem) test verisi olarak ayırmıştık. compare_models fonksiyonunun çıktısındaki tabloda bulunan tüm değerlendirme metrikleri, yalnızca eğitim kümesine ($\%70$) dayalı çapraz doğrulanmış sonuçlardır.
Şimdi tuned_catboost nesnesi içinde depolanan eğitilmiş ve hiperparametrelerine ince ayar çekilmiş modelimizi kullanarak, test kümesindeki gözlemleri tahmin edeceğiz ve çapraz doğrulama sonuçlarından önemli ölçüde farklı olup olmadığını görmek için ölçütleri değerlendireceğiz.
predict_model(tuned_catboost)

Test veri kümesinden elde edilen belirtme katsayısı R2, $0.9641$’dir ve tuned_catboost çapraz doğrulama sonuçlarından elde edilen R2 ise $0.9636$’dır. Bu önemli bir fark değildir. Test kümesi ve çapraz doğrulama sonuçları arasında büyük bir farklılık varsa, bu normalde aşırı uyumu gösterir, ancak aynı zamanda birkaç başka faktörden de kaynaklanabilir ve daha fazla araştırma gerektirir
Elimizdeki sonuçlar güzel olduğuna göre modeli sonlandırabiliriz.
Modeli Sonlandırmak
Modelin sonlandırılması, deneydeki son adımdır. finalize_model fonksiyonu, modeli test kümesi (bu durumda $\%30$) dahil olmak üzere tüm veri kümesine uyum sağlatır (fitting). Bu fonksiyonun amacı, üretimde dağıtılmadan önce tüm veri kümesi üzerinde modeli eğitmektir.
final_catboost = finalize_model(tuned_catboost)
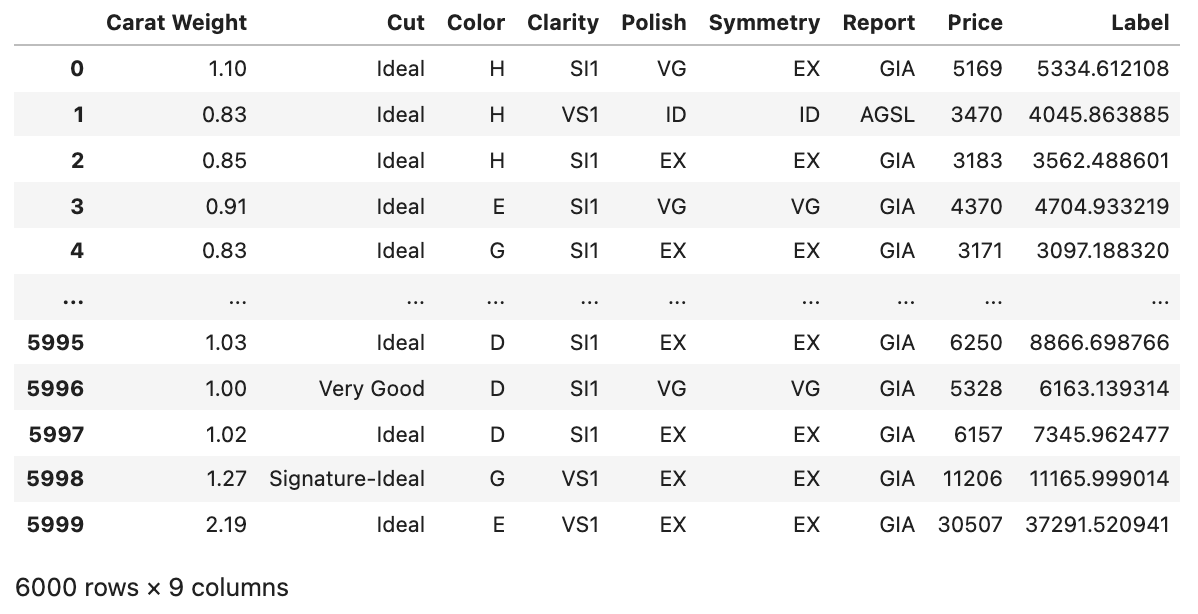
Nihai modeli, tam veri kümesi üzerinde çalıştırarak tüm tahminleri elde edebiliriz:
predict_model(final_catboost, data = dataset)
Modeli kaydetmek
Modelimizi sonlandırdıktan sonra kaydetmemiz gerekmektedir. Diğer uygulamalara aktarılabilen ve bu uygulamalar tarafından tüketilebilen bir dosya olarak kaydetmek için aşağıdaki kodu çalıştırınız:
save_model(model = final_catboost, model_name = 'myMLmodel', model_only = False)
# Transformation Pipeline and Model Successfully Saved
# (Pipeline(memory=None,
# steps=[('dtypes',
# DataTypes_Auto_infer(categorical_features=['Cut', 'Color',
# 'Clarity', 'Polish',
# 'Symmetry',
# 'Report'],
# display_types=True, features_todrop=[],
# id_columns=[], ml_usecase='regression',
# numerical_features=['Carat Weight'],
# target='Price', time_features=[])),
# ('imputer',
# Simple_Imputer(categorical_strategy='not_available',
# fill_va...
# ('rem_outliers', 'passthrough'), ('cluster_all', 'passthrough'),
# ('dummy', Dummify(target='Price')),
# ('fix_perfect', Remove_100(target='Price')),
# ('clean_names', Clean_Colum_Names()),
# ('feature_select', 'passthrough'), ('fix_multi', 'passthrough'),
# ('dfs', 'passthrough'), ('pca', 'passthrough'),
# ['trained_model',
# <catboost.core.CatBoostRegressor object at 0x7f9cbfa44a30>]],
# verbose=False),
# 'myMLmodel.pkl')
PyCaret’te bir modeli kaydettiğinizde, setup() fonksiyonunda tanımlanan konfigürasyona dayalı tüm dönüşüm (transformation) iletim hattı oluşturulur. Tüm karşılıklı bağımlılıklar otomatik olarak düzenlenir.
Birinci görev olan model eğitimini ve dağıtım için bir model seçmeyi bitirdik. Nihai veri dönüştürme iletim hattı ve makine öğrenmesi modeli, artık save_model() fonksiyonunda tanımlanan konumun altındaki yerel sürücüde bir pickle nesnesi olarak kaydedildi. (Bu örnek için myMLmodel.pkl)
Görev 2 — Web Uygulaması İnşaa Etme
Artık veri iletim hattımız ve modelimiz hazır olduğuna göre, bunlara bağlanabilen ve gerçek zamanlı olarak yeni veriler üzerinde tahminler üretebilen bir web uygulaması oluşturmaya başlayacağız. Bu uygulamanın iki bölümü vardır:
- Ön uç (HTML kullanılarak tasarlanmıştır)
- Arka uç (Python’da Flask kütüphanesi kullanılarak geliştirilmiştir)
Web Uygulamasının Ön Ucu
Genel olarak, web uygulamalarının ön ucu (front-end), bu eğiticinin odak noktası olmayan HTML kullanılarak oluşturulur. Bir veri girdi formu tasarlamak için basit bir HTML şablonu ve bir CSS stil sayfası kullanırız. Bunun için Visual Studio Code uygulamasını açınız ve DiamondApp klasörü altında templates isminde yeni bir klasör yaratınız. Bu klasörün altında index.html isminde boş bir HTML dosyası yaratınız.

7 tane bağımsız değişkenimiz olduğu için kullanıcı tarafından doldurulması gereken 7 farklı girdi alanı oluşturmamız gerekmektedir:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Predict Insurance Bill</title>
<link href='https://fonts.googleapis.com/css?family=Pacifico' rel='stylesheet' type='text/css'>
<link href='https://fonts.googleapis.com/css?family=Arimo' rel='stylesheet' type='text/css'>
<link href='https://fonts.googleapis.com/css?family=Hind:300' rel='stylesheet' type='text/css'>
<link href='https://fonts.googleapis.com/css?family=Open+Sans+Condensed:300' rel='stylesheet' type='text/css'>
<link type="text/css" rel="stylesheet" href="">
</head>
<body>
<div class="login">
<h1>Predict the Price of the Diamond</h1>
<!-- Form to enter new data for predictions -->
<form action=""method="POST">
<input type="text" name="carat_weight" placeholder="Carat Weight" required="required" /><br>
<input type="text" name="cut" placeholder="Cut (Ideal / Very Good / Good / Signature-Ideal / Fair)" required="required" /><br>
<input type="text" name="color" placeholder="Color (G / H / F / I /E / D)" required="required" /><br>
<input type="text" name="clarity" placeholder="Clarity (SI1 / VS2 / VS1 / VVS2 / VVS1 / IF / FL)" required="required" /><br>
<input type="text" name="polish" placeholder="Polish (EX / VG / ID / G)" required="required" /><br>
<input type="text" name="symmetry" placeholder="Symmetry (VG / EX / G / ID)" required="required" /><br>
<input type="text" name="report" placeholder="Report(GIA / AGSL)" required="required" /><br>
<button type="submit" class="btn btn-primary btn-block btn-large">Predict</button>
</form>
<br>
<br>
</div>
</body>
</html>
CSS Stil Sayfası (CSS Style Sheet)
CSS (Cascading Style Sheets), HTML öğelerinin bir ekranda nasıl görüntülendiğini tanımlar. Uygulamanızın düzenini (layout) kontrol etmenin etkili bir yoludur. Stil sayfaları, arka plan rengi, yazı tipi boyutu, yazı tipi rengi, kenar boşlukları vb. gibi bilgileri içerir. Harici olarak bir .css dosyasına kaydedilirler. CSS, HTML’e bağlantılıdır ve HTML dosyasında bir satır kod ile refere edilirler:
<link type="text/css" rel="stylesheet" href="">
NOT: Flask uygulamanızın içinde “static” adlı bir klasör oluşturmanız ve ardından tüm CSS dosyalarınızı oraya koymanız gerekmektedir.
Web Uygulamasının Arka Ucu
Bir web uygulamasının arka ucu, bir Flask yazılım çerçevesi kullanılarak geliştirilir. Yeni başlayanlar için Flask’ı Python’daki diğer kütüphaneler gibi içe aktarabileceğiniz bir kütüphane olarak düşünebilirsiniz.
Bu adımda, Flask uygulamanızın kodunu yeni bir dosyada oluşturacaksınız. Bu dosyanın adını da app.py olarak koyalım. app.py dosyası ana klasörde yer alması gerekmektedir.

İlk olarak gerekli kütüphaneleri içe aktaralım
Diğer herhangi bir Python sınıfı (class) nesnesi gibi, bu uygulama, tarayıcıdan gelen istekleri (requests) işleyerek (bu örnek için kulanıcının vermiş olduğu girdiler) bizim için tüm ağır yükleri kaldıracak olan Flask sınıfının bir nesnesinden başka bir şey değildir. Bu nedenle app = Flask(__name__) kod satırı ile bu nesneyi (object) yaratıyoruz.
Daha sonra, kaydettiğimiz modelimizin pickle nesnesini Pycaret kütüphanesindeki load_model fonksiyonu ile geri yükleyelim. Daha sonra veri kümemizde bulunan bağımsız değişkenlerin isimlerinden oluşan bir liste oluşturalım:
from flask import Flask,request, url_for, redirect, render_template, jsonify
from pycaret.regression import *
import pandas as pd
import pickle
import numpy as np
app = Flask(__name__)
model = load_model('myMLmodel')
cols = ['Carat Weight', 'Cut', 'Color', 'Clarity', 'Polish', 'Symmetry', 'Report']
index() görüntüleme fonksiyonu, argüman olarak index.html dosyasını alan render_template() çağrısının sonucunu döndürecektir. flask.render_template() ana dizinimizde oluşturduğumuz templates klasöründe bu index.html dosyasını arar ve son kullanıcı için dinamik olarak bir HTML sayfası oluşturur/işler
@app.route('/')
def index():
return render_template("index.html")
Ana sayfayı index.html olarak ayarladık. /predict‘e POST isteğini kullanarak form değerlerini gönderirken, tahmin edilen fiyat değerini geri alacağız:
@app.route('/predict',methods=['POST'])
def predict():
int_features = [x for x in request.form.values()]
final = np.array(int_features)
data_unseen = pd.DataFrame([final], columns = cols)
prediction = predict_model(model, data=data_unseen, round = 0)
prediction = int(prediction.Label[0])
return render_template('index.html', pred= "Price of the diamond will be $ {:,.2f}".format (prediction))
/results‘a başka bir POST isteği yapılarak sonuç gösterilebilir. /results, JSON girdilerini alır, bir tahmin yapmak için eğitilmiş modeli kullanır (Pycaret kütüphanesinin predict_model fonksiyonunu kullanarak) ve bu tahmini API uç noktasından (endpoint) erişilebilen JSON biçiminde döndürür:
@app.route('/results',methods=['POST'])
def results():
data = request.get_json(force=True)
data_unseen = pd.DataFrame([data])
prediction = predict_model(model, data=data_unseen)
output = prediction.Label[0]
return jsonify(output)
Uygulamamızın kodu artık hazır. Uygulamayı Heroku’da yayınlamadan önceki son adım, web uygulamasını yerel olarak test etmektir. Bir Terminal penceresi açınız ve bilgisayarınızda app.pynin kayıtlı olduğu klasöre gidin,i. Python dosyasını aşağıdaki kodla çalıştırınız:
(base) Arat-MacBook-Pro-2:DiamondApp mustafamuratarat$ python app.py
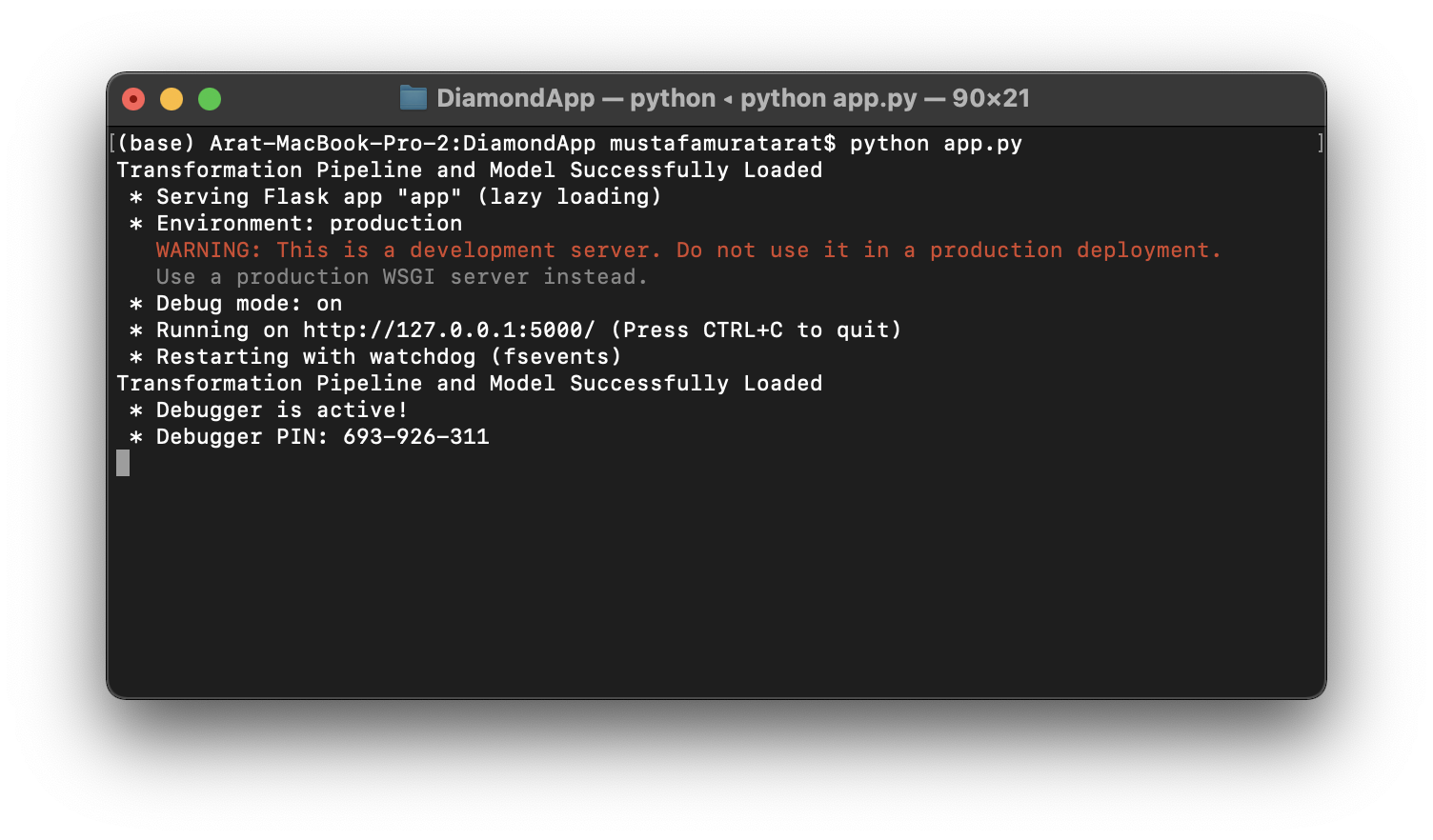
Kod çalıştıktan sonra, URL’yi bir tarayıcıya kopyalayın ve yerel makinenizde barındırılan bir web uygulamasını açmalıdır: http://127.0.0.1:5000/
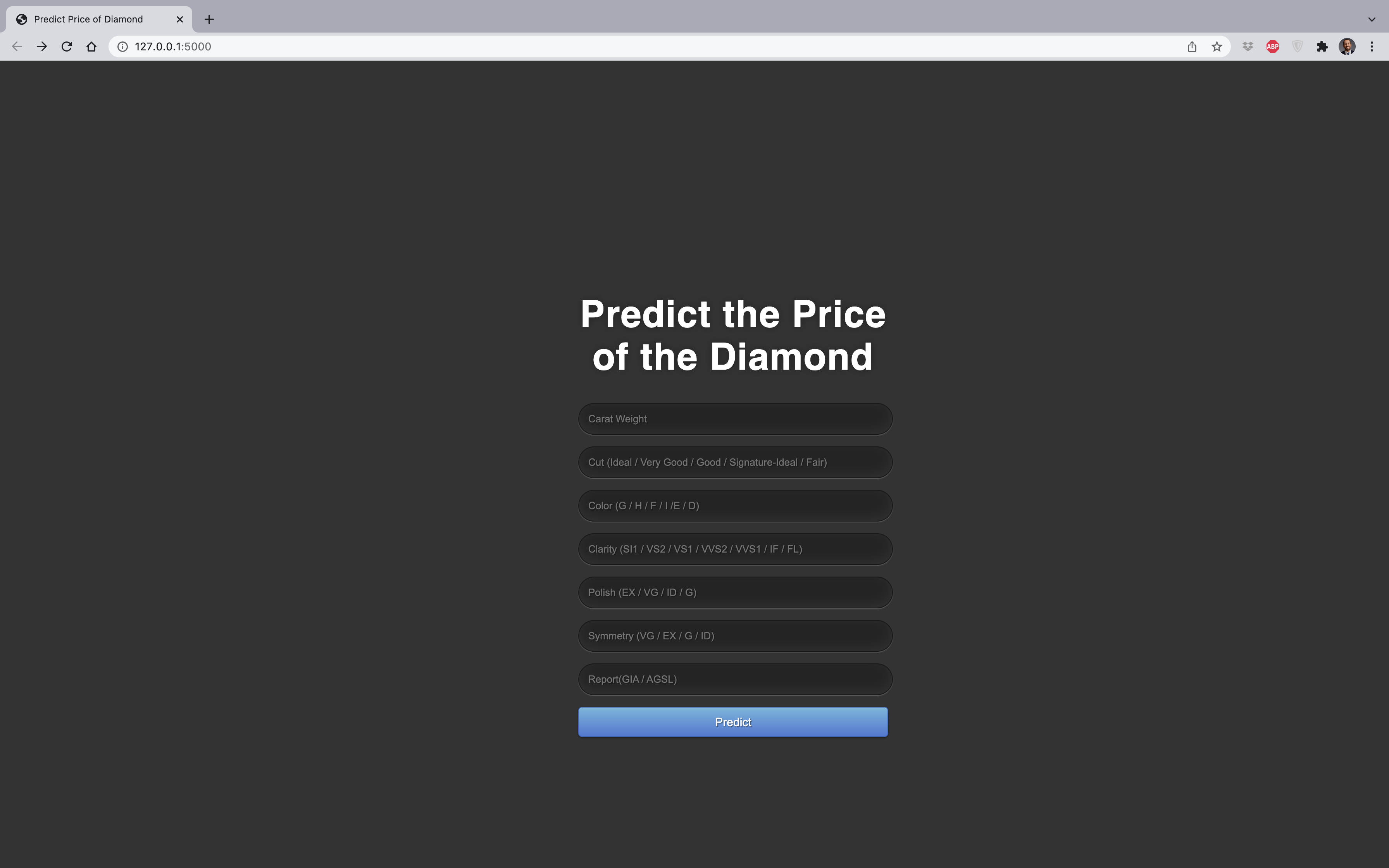
Tahmin işlevinin çalışıp çalışmadığını görmek için test değerleri girmeyi deneyiniz:
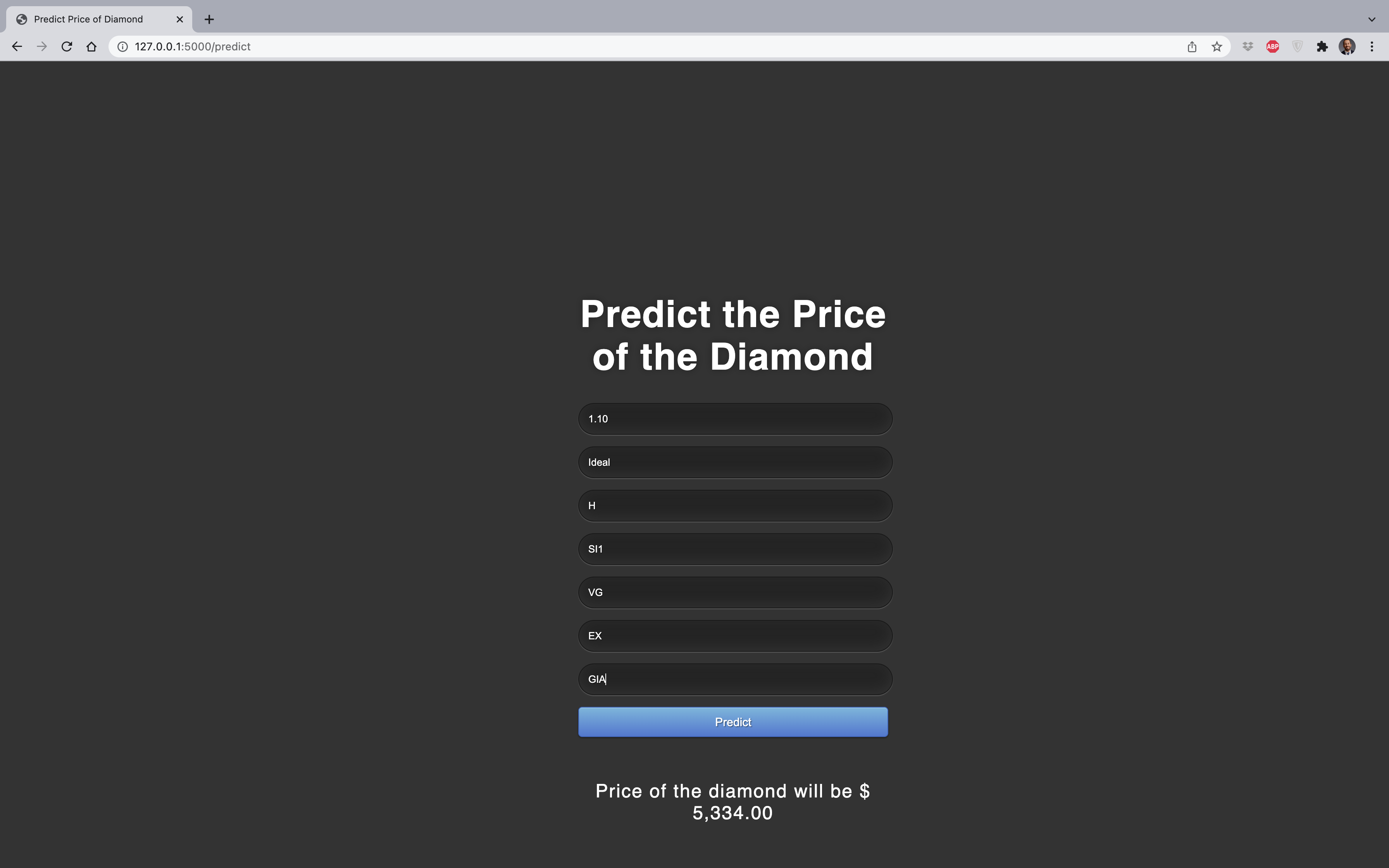
Tebrikler! Pycaret ve Flask kullanarak artık ilk makine öğrenmesi uygulamanızı oluşturdunuz. Şimdi bu uygulamayı yerel makinenizden buluta taşımanın zamanı geldi, böylece diğer insanlar bir Web URL’si ile kullanabilirler.
Görev 3 — Web Uygulamasını Heroku’da Dağıtın
Artık model eğitildiğine, makine öğrenmesi iletim hattı hazır olduğuna ve uygulama yerel makinemizde test edildiğine göre, Heroku’da dağıtımımızı başlatmaya hazırız. Uygulama kaynak kodunuzu Heroku’ya yüklemenin birkaç yolu vardır. En basit yol, bir GitHub deposunu Heroku hesabınıza bağlamaktır.
requirements.txt dosyasını oluşturma
Uygulama kodunun yazımı tamamlandığında tüm Python bağımlılıklarının (dependencies) olduğu requirements.txt dosyasını oluşturmak için pipreqs kütüphanesini kullanabiliriz. Bu kütüphane yüklü değilse, pip3 install pipreqs komutu ile kişisel bilgisayarınıza yükleyebilirsiniz.
Daha sonra bir Terminal penceresinden, app.py dosyamızın olduğu klasöre gidelim ve pipreqs ./ komutu ile kullanılan tüm paketleri requirements isimli metin dosyasına yazdıralım:
(base) Arat-MacBook-Pro-2:DiamondApp mustafamuratarat$ pipreqs ./
INFO: Successfully saved requirements file in ./requirements.txt
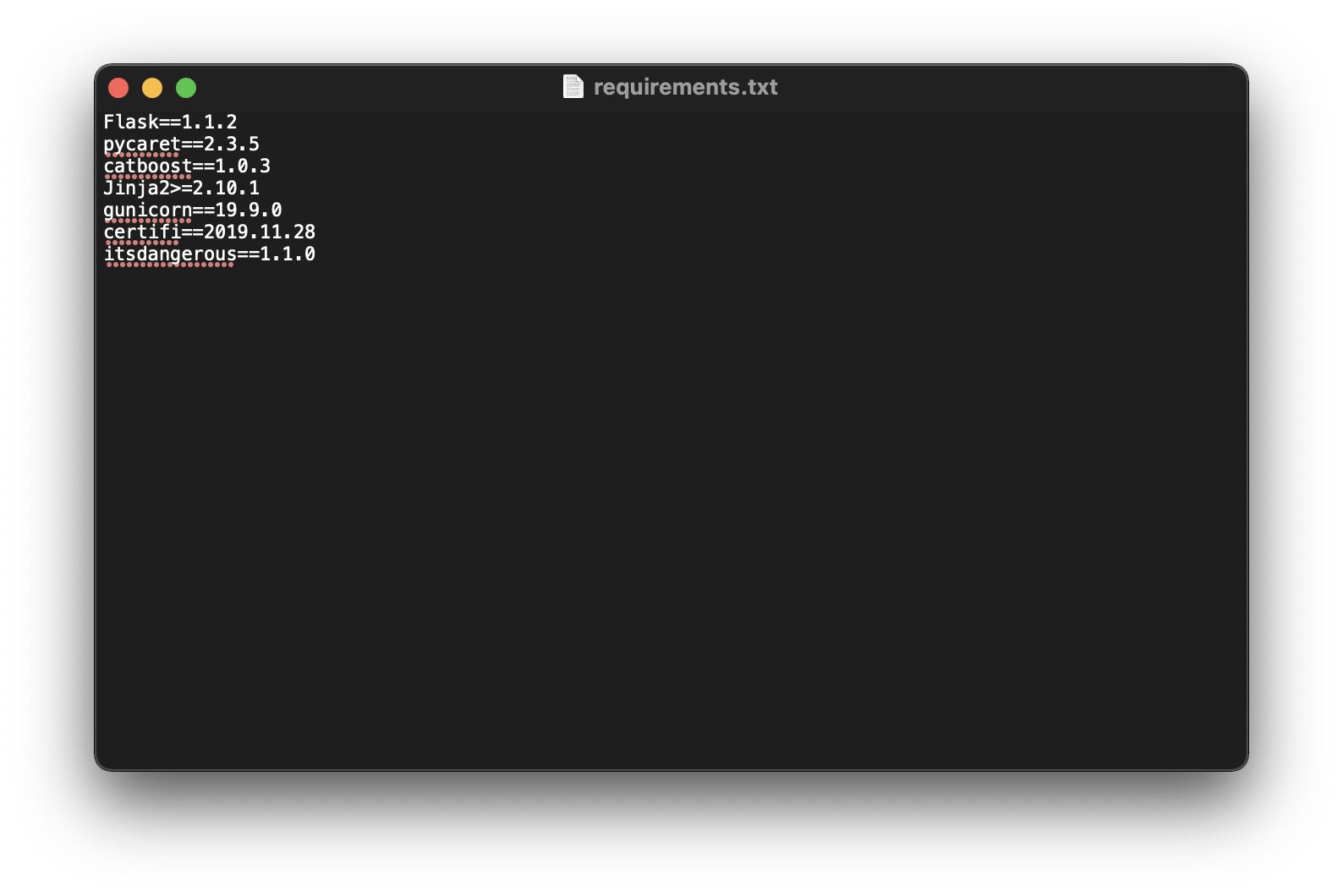
requirements.txt metin dosyasını oluşturmamızın sebebi, uygulamayı canlı ortama dağıtırken kullanacağımız bulut sunucusunun gerekli gereksinimleri yüklemesi içindir.
Procfile oluşturma
Heroku’nun istediği diğer bir dosya ise Procfile’dır. Visual Studio Code kullanılarak kolaylıkla oluşturulabilir. Procfile, biri uygulamaya girdiğinde, önce hangi dosyanın çalıştırılması gerektiğini belirten ve web sunucusuna başlatma talimatları sağlayan basit bir kod satırıdır. Bu eğiticide uygulama dosyamızın adı app.py ve uygulamanın adı da app çünkü app = Flask(__name__) (dolayısıyla app:app).

Web uygulama klasörümüz olan DiamondApp‘in son hali şu şekildedir:

Şimdi tüm bu dosyaların olduğu DiamondApp klasörünü Github’da bir depoya yükleyelim:
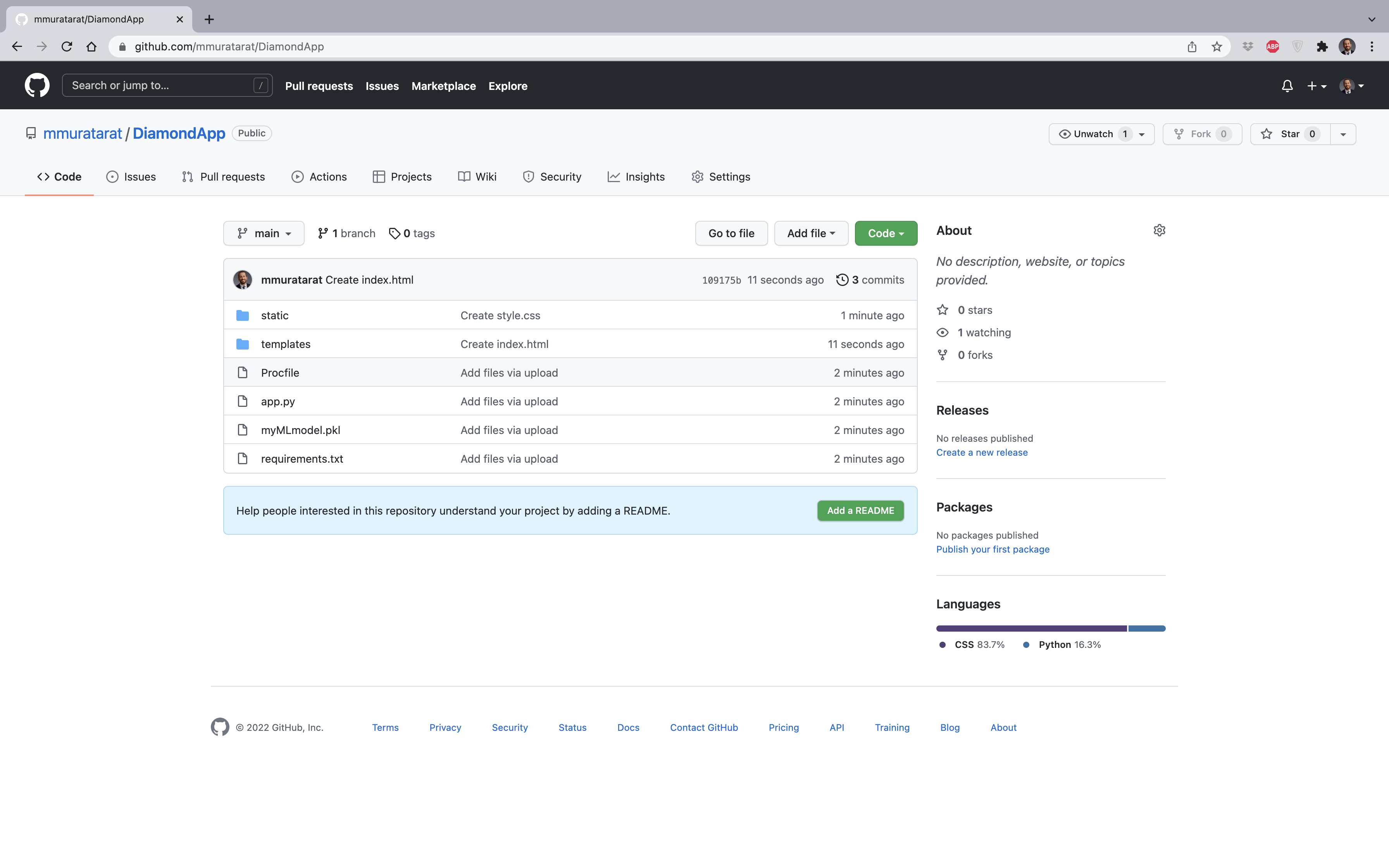
Adım 1 — heroku.com’a kayıt olun ve New (Yeni) > Create new app (Yeni uygulama oluştur)‘a tıklayınız:

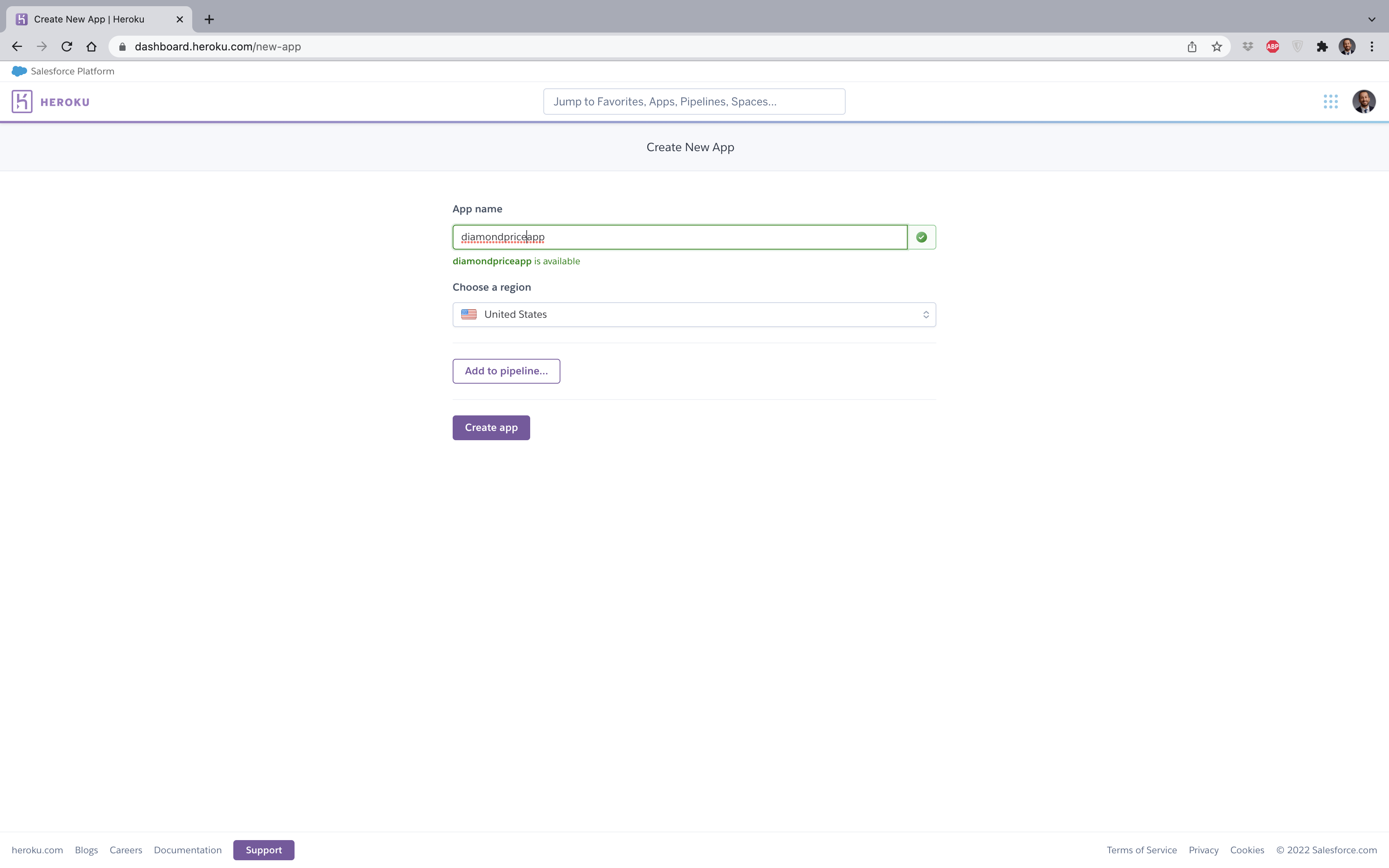
Adım 2 — Uygulama adını ve bölgesini giriniz. Daha sonra Create app (Uygulamayı oluştur) butonuna tıklayınız:
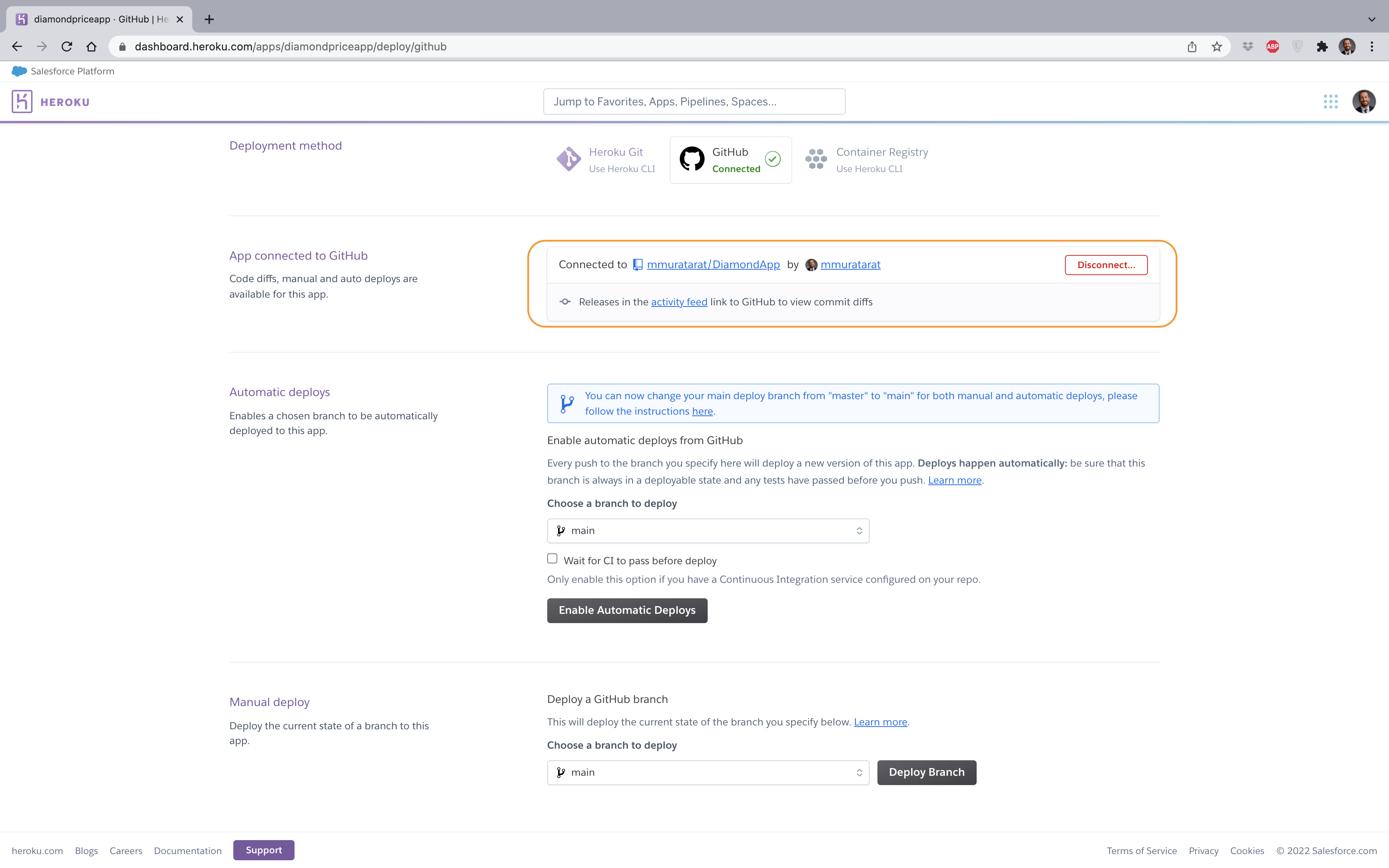
Adım 3 — Uygulama kodunuzun barındırıldığı GitHub deponuza bağlanınız:
Adım 4 — Dalı (branch) dağıtınız:

Adım 5 — Bir kaç dakika boyunca gerekli bağımlılıkların yüklenmesini bekleyiniz:
ve BOOM! Uygulamanız üretim ortamına dağıtıldı ve kullanılma hazır!
https://diamondpriceapp.herokuapp.com/
Oluşturduğumuz tüm dosyaları burada bulunan Github deposunda bulabilirsiniz. Github sayfasındaki dosyaları her güncellemenizde, canlı uygulama da yeniden inşaa edilip, güncellenecektir.