29 dakikada okunabilir.
MLOps Serisi III - Bir Makine Öğrenmesi Yazılımının Üç Aşaması
MLOps (Makine Öğrenmesi operasyonları) isimli serinin üçüncü kısımı, ilk yazıda olduğu gibi, Dr. Larysa Visengeriyeva, Anja Kammer, Isabel Bär, Alexander Kniesz, ve Michael Plöd tarafından INNOQ için yazılmış “Three Levels of ML Software” isimli yazı. İyi Okumalar!
Bir Makine Öğrenmesi Yazılımının Üç Aşaması
Makine Öğrenmesi / Yapay Zeka, yeni uygulamalar ve endüstriler tarafından hızla benimsenmektedir. Daha önce bahsedildiği gibi, bir makine öğrenmesi projesinin amacı, toplanmış verileri kullanarak ve bu verilere makine öğrenmesi algoritmalarını uygulayarak istatistiksel bir model oluşturmaktır. Ancak, başarılı makine öğrenmesi tabanlı yazılım projeleri oluşturmak halen zordur çünkü her makine öğrenmesi tabanlı yazılımın üç ana bileşeni yönetmesi gerekir: Veri, Model ve Kod. Makine Öğrenmesi Modeli Operasyonelleştirme Yönetimi - MLOps, bir DevOps uzantısı olarak, Makine Öğrenmesi modellerini tasarlama, oluşturma ve üretime dağıtma konusunda etkili uygulamalar ve süreçler sunar. Burada, Makine Öğrenmesi tabanlı yazılımın geliştirilmesinde yer alan temel teknik metodolojileri, yani Veri Mühendisliği, Makine Öğrenmesi Model Mühendisliği ve Yazılım Mühendisliği’ni tanımlayacağız.
Oluşturacağınız iletim hattının her adımında öğrendiğiniz her şeyi belgelemenizi öneririz.
Veri: Veri Mühendisliği İletim Hatları
Herhangi bir makine öğrenmesi iş akışının temel parçasının Veri olduğundan daha önce bahsetmiştik. İyi veri kümelerinin toplanması, Makine Öğrenmesi modelinin kalitesi ve performansı üzerinde büyük bir etkiye sahiptir. Literatürdeki meşhur alıntı
“Çöp içeri çöp dışarı (Garbage In, Garbage Out)”,
makine öğrenmesi bağlamında, bir makine öğrenmesi modelinin yalnızca elinizdeki verileriniz kadar iyi olduğu anlamına gelir. Bu nedenle, bir makine öğrenmesi modelinin eğitilmesi için kullanılan veriler dolaylı olarak üretim sisteminin genel performansını etkilemektedir. Veri kümesinin miktarı ve kalitesi genellikle elinizdeki probleme göre değişebilir ve deneysel olarak incelemesi yapılabilir.
Önemli bir adım olan veri mühendisliğinin çok zaman alıcı olduğu bildirilmektedir. Bir makine öğrenmesi projesinde zamanımızın çoğunu veri kümeleri oluşturmak, verileri temizlemek ve dönüştürmek için harcayabiliriz.
Veri mühendisliği iletim hattı, mevcut veriler üzerinde bir işlemler dizisi oluşturmak için yaratılır. Bu işlemlerin nihai amacı, makine öğrenmesi algoritmaları için eğitim ve test veri kümeleri oluşturmaktır. Aşağıda, Veri Alınımı (Data Ingestion), Keşif ve Doğrulama (Exploration and Validation), Veri Düzenleme (Temizleme)(Data Wrangling (Cleaning)) ve Veri Ayırma (Data Splitting) gibi veri mühendisliği iletim hattı oluştururken takip edilmesi gereken her aşamayı açıklayacağız.
Veri Alınımı (Data Ingestion)
Veri Alınımı - Dahili / harici veritabanları, veri reyonları, OLAP küpleri, veri ambarları, OLTP sistemleri, Spark, HDFS ve bunlar gibi çeşitli sistemleri, yazılım iskeletlerini ve formatları kullanarak veri toplama. Bu adım, sentetik veri oluşturmayı veya veri zenginleştirmeyi de içerebilir. Bu adım için en iyi uygulamalar, maksimum düzeyde otomatikleştirilmesi gereken aşağıdaki eylemleri içerir:
Veri Kaynaklarını Tanımlama: Veriyi bulun ve kaynağını belgeleyin
Alan Tahmini: verinin depolama alanında ne kadar yer kaplayacağını kontrol edin.
Alan Konumu: Yeterli depolama alanına sahip bir çalışma alanı oluşturun.
Veri Elde Etme: Verileri alın ve verilerin kendisini değiştirmeden kolayca işlenebilecek bir formata dönüştürün.
Verileri Yedekleyin: Her zaman verilerin bir kopyası üzerinde çalışın ve orijinal veri kümesini saklayın.
Gizlilik Uyumluluğu: Genel Veri Koruma Yasasına (GDPR - General Data Protection Regulation) uyumluluğunu sağlamak için hassas bilgilerin silindiğinden veya korunduğundan (örneğin, anonimleştirildiğinden) emin olun.
Meta Veri Kataloğu: Boyut, format, diğer adlar (rumuz veya takma ad), son değiştirilme zamanı ve erişim kontrol listeleri gibi temel bilgileri kaydederek veri kümesinin meta verilerini belgelemeye başlayın. (Daha fazla bilgi için buraya tıklayınız.)
Test Verisi: Bir test kümesi örnekleyin, bir kenara koyun ve “veri gözetleme (data snooping)” yanlılığından kaçınmak için ona asla bakmayın. Bu test kümesini kullanarak belirli bir makine öğrenmesi modeli seçiyorsanız hata yapıyorsunuz. Bu, çok iyimser ve üretimde iyi performans göstermeyecek bir makine öğrenmesi modeli seçimine yol açacaktır.
Keşif ve Doğrulama (Exploration and Validation)
Keşif ve Doğrulama - Verilerin içeriği ve yapısı hakkında bilgi edinmek için veri profili oluşturmayı kapsar. Bu adımın çıktısı, maksimum, minimum, ortalama değerler gibi bir meta veri kümesidir. Veri doğrulama işlemleri, bazı hataları tespit etmek için veri kümesini tarayan kullanıcı tanımlı hata algılama fonksiyonlarıdır. Doğrulama, veri kümesi doğrulama rutinlerini (hata tespit yöntemleri) çalıştırarak verilerin kalitesini değerlendirme sürecidir. Örneğin, “adres” özniteliği (feature) için adres bileşenleri tutarlı mıdır? Adres ile doğru posta kodu ilişkilendirilmiş midir? İlgili niteliklerde (attributes) kayıp değerler var mı? Bu adım için en iyi uygulamalar aşağıdaki eylemleri içerir:
Hızlı Uygulama Geliştirme (RAD - Rapid Application Development) araçlarını kullanın: Jupyter not defterlerini kullanmak, verinin keşfi ve veri üzerinde yapılacak denemelerin kayıtlarını tutmanın iyi bir yoludur.
Öznitelik Profili Oluşturma: Her öznitelikle ilgili meta verileri alın ve belgeleyin, örneğin:
İsim
Kayıt Sayısı
Veri Tipi (kategorik, sayısal (nümerik), int (tamsayı) / float (kayan noktalı sayı), metin, yapılandırılmış vb.)
Sayısal Ölçüler (sayısal veriler için min, maks, ortalama, medyan vb.)
Kayıp değerlerin miktarı (veya “kayıp değer oranı” = kayıp değerlerin sayısı / Kayıt sayısı)
Dağılım türü (Gauss, uniform (tekdüze), logaritmik, vb.)
Etiket (Label) Özniteliği Tanımlama: Denetimli öğrenme görevleri için hedef öznitelik(ler)i tanımlayın.
Veri Görselleştirme: Değer dağılımı için görsel bir temsil oluşturun.
Nitelik Korelasyonu: Nitelikler arasındaki korelasyonları hesaplayın ve analiz edin.
Ek Veriler: Modeli oluşturmak için yararlı olacak verileri tanımlayın (“Veri Alınımı” adımına geri dönün).
Veri Düzenleme (Temizleme)(Data Wrangling (Cleaning))
Veri Düzenleme (Temizleme) - Verilerin şemasının biçimini değiştirebilecek belirli öznitelikleri yeniden biçimlendirerek veya yeniden yapılandırarak, verileri programatik olarak düzenlediğiniz veri hazırlama adımı. Tüm bu fonksiyonellikleri gelecekteki verilerde yeniden kullanmak için veri iletim hattındaki tüm veri dönüşümleri için komut dosyaları (betikler) veya fonksiyonları yazmanızı öneririz.
Dönüşümler: Uygulamak isteyebileceğiniz gelecek vaat eden dönüşümleri tanımlayın.
Aykırı Değerler: Aykırı değerleri düzeltin veya bu aykırı değerlerden kurtulun (isteğe bağlı).
Kayıp Değerler: Kayıp değerleri (örneğin, sıfır, ortalama, veya medyan ile) doldurun veya kayıp değer içeren satırları veya sütunları silin.
Alakasız Veriler: Görev için yararlı bilgiler sağlamayan özniteliklerden kurtulun (öznitelik mühendisliği ile ilgili).
Verileri Yeniden Yapılandırma: Aşağıdaki işlemleri içerebilir (“Principles of Data Wrangling” kitabından):
Sütunları taşıyarak kayıt alanlarını yeniden sıralama
Değerleri ayıklayarak yeni kayıt alanları oluşturma
Birden çok kayıt alanını tek bir kayıt alanında birleştirme
Kayıtların bazılarını silerek veri kümelerini filtreleme
Veri kümesinin ve kayıtlarla ilişkili alanların ayrıntı düzeyini (granularity), birleştirme (aggregation) ve pivotlama yaparak değiştirme.
Veri Ayırma (Data Splitting)
Veri Ayırma - Makine Öğrenmesi modelini oluşturmak için temel makine öğrenmesi aşamalarında kullanılacak verileri eğitim (%80), doğrulama ve test kümesi olmak üzere üçe ayırın.
Model: Makine Öğrenmesi İletim Hattı
Makine öğrenmesi iş akışının temeli, bir makine öğrenmesi modeli elde etmek için makine öğrenmesi algoritmalarını yazma ve çalıştırma aşamasıdır. Model mühendisliği iletim hattı genellikle bir veri bilimi ekibi tarafından kullanılır ve nihai bir modele götüren bir dizi işlemi içerir. Bu işlemler, Modelin Eğitimi, Modelin Değerlendirilmesi, Modelin Test Edilmesi ve Modelin Paketlenmesi adımlarını içerir. Bu adımları olabildiğince otomatikleştirmenizi öneririz.
Modelin Eğitimi
Modelin Eğitimi - Bir modeli eğitmek amacıyla, makine öğrenmesi algoritmasını eğitim verilerine uygulama süreci. Ayrıca, modelin eğitimi sırasında uygulanması gereken hiperparametrelere ince ayar verilmesi ve öznitelik mühendisliği adımlarını da içerir. Aşağıdaki liste, Aurélien Géron tarafından yazılan “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” isimli kitaptan alınmıştır.
Öznitelik mühendisliği şunları içerebilir:
Sürekli öznitelikleri ayrıklaştırın (kategorikleştirin)
Öznitelikleri ayrıştırın (örneğin, Kategorik, tarih / saat vb.)
Özniteliklerin dönüşümlerini ekleyin (örneğin, log (x), sqrt (x), x2, vb.)
Öznitelikleri birleştirerek kullanışlı yeni özellikler elde edin
Öznitelik ölçekleme: Öznitelikleri standartlaştırın veya normalleştirin
Üretime koymak istediğimiz yeni bir özelliğe hızlı bir şekilde geçiş yapmak için yeni öznitelikler hızla eklenmelidir. Daha fazla bilgi için Alice Zheng ve Amanda Casari tarafından yazılan “Feature Engineering for Machine Learning. Principles and Techniques for Data Scientists” isimli kitaba göz atınız.
Model Mühendisliği, yinelemeli bir süreç olabilir ve aşağıdaki iş akışını içerebilir:
Her Makine Öğrenmesi modelinin spesifikasyonu (bu modeli oluşturan kod) bir kod incelemesinden geçmeli ve versiyonlanmalıdır.
Standart parametreleri kullanarak farklı kategorilerden (örneğin, doğrusal regresyon, lojistik regresyon, k-ortalamalar, naif Bayes, Destek Vektör Makineleri, Rastgele Ağaçlar, vb.) birçok Makine Öğrenmesi modelini eğitin.
Performanslarını ölçün ve karşılaştırın. Her model için, N-parça çapraz doğrulama kullanın ve performans ölçüsünün ortalamasını ve standart sapmasını N parça üzerinde hesaplayın.
Hata Analizi: Makine öğrenmesi modellerinin yaptığı hata türlerini analiz edin.
Daha fazla öznitelik seçimi ve mühendisliği gerçekleştirin.
Farklı türde hatalar yapan modelleri tercih ederek, en umut vadeden ilk üç ila beş modeli belirleyin.
Çapraz doğrulama kullanarak hiperparametrelerin ayarlanması. Lütfen veri dönüştürme seçeneklerinin de hiperparametreler olduğunu unutmayın. Hiperparametreler için rastgele arama (random search), ızgara aramasına (grid search) tercih edilir.
Çoğunluk oylaması (majority vote), torbalama (bagging), hızlandırma (boosting) veya istifleme (stacking) gibi Topluluk yöntemlerini (Ensemble methods) göz önünde bulundurun. Makine öğrenmesi modellerini birleştirmek, onları ayrı ayrı çalıştırmaktan daha iyi performans üretmelidir. Daha fazla bilgi için Zhi-Hua Zhou tarafından yazılan “Ensemble Methods: Foundations and Algorithms” isimli kitaba göz atınız.
Modelin Değerlendirilmesi
Modelin Değerlendirilmesi - Makine öğrenmesi modelini üretimde son kullanıcıya sunmadan önce orijinal işletme hedeflerini karşıladığından emin olmak için eğitimli modeli doğrulayın.
Modelin Test Edilmesi
Modelin Test Edilmesi - Nihai Makine Öğrenmesi modeli eğitildikten sonra, son olarak “Model Kabul Testi” gerçekleştirilerek genelleme hatasını tahmin etmek için daha önceden görülmemiş veri kümesi üzerinde bu modelin performansının ölçülmesi gerekir.
Modelin Paketlenmesi
Modelin Paketlenmesi - Nihai makine öğrenmesi modelini, herhangi bir uygulama tarafından tüketilecek modeli tanımlayan belirli bir biçime (ör. PMML, PFA veya ONNX) aktarma işlemi. Makine öğrenmesi modelinin nasıl paketlenebileceğini aşağıdaki “Makine Öğrenmesi Modeli serileştirme formatları” bölümünde ele alıyoruz.
Makine öğrenmesi iş akışlarının farklı biçimleri
Bir makine öğrenmesi modelinin çalıştırılması, birkaç mimari stil gerektirebilir. Aşağıda, iki boyutta sınıflandırılan dört mimari deseni tartışıyoruz:
-
Makine Öğrenmesi Modelinin Eğitimi ve
-
Makine Öğrenmesi Modelinden Tahmin Yapma
Konuyu daha basit tutabilmek için, denetimli öğrenme (supervised), denetimsiz öğrenme (unsupervised), yarı denetimli öğrenme (semi-supervised) ve Pekiştirmeli Öğrenme (reinforcement learning) gibi elimizdeki makine öğrenmesi algoritmasının türünü ifade eden üçüncü boyutu yani 3. Makine Öğrenmesi Modelinin Türü‘nü göz ardı ettiğimizi lütfen unutmayın.
Bir Makine Öğrenmesi Modelinin Eğitimini gerçekleştirmenin iki yolu vardır:
- Çevrimdışı öğrenme (diğer bir deyişle yığın veya statik öğrenme): Model, önceden toplanmış bir dizi veri üzerinde eğitilir. Üretim ortamına dağıtıldıktan sonra, elimizdeki makine öğrenmesi modeli yeniden eğitilene kadar değişmez çünkü model çok sayıda gerçek canlı veri görecek ve kaba tabiri ile eskiyecektir. Bu fenomen, “modelin bozunması” (model decay) olarak adlandırılır ve model dikkatle takip edilmelidir.
- Çevrimiçi öğrenme (diğer adıyla dinamik öğrenme): Yeni veriler geldikçe model düzenli olarak yeniden eğitilmektedir, örneğin veri akarak yani durmaksızın eş zamanlı geliyorsa. Bu genellikle, makine öğrenmesi modelindeki zamansal etkileri analiz edebilmek için sensör veya hisse senedi alım satım verileri gibi zaman serisi verilerini kullanan makine öğrenmesi sistemleri için geçerlidir.
İkinci boyut, bir makine öğrenmesi modelinden tahminde bulunmak için gerekli mekaniği tanımlayan Makine Öğrenmesi Modelinden Tahmin Yapmadır. Bu seçeneği de iki kısıma ayırabiliriz:
- Yığın tahminler: Üretime dağıtılmış bir makine öğrenmesi modeli, geçmiş girdi verilerine dayalı bir dizi tahmin yapar. Bu genellikle zamana bağlı olmayan veriler için veya çıktı olarak gerçek zamanlı tahminler elde etmenin kritik olmadığı durumlarda yeterlidir.
- Gerçek zamanlı tahminler (diğer adıyla isteğe bağlı (on-demand) tahminler): Tahminler, talep anında (yani isteğe bağlı olarak) mevcut girdi verileri kullanılarak gerçek zamanlı olarak oluşturulur.
Bu iki boyuta karar verdikten sonra, makine öğrenmesi modellerinin operasyonel hale getirilmesini dört farklı makine öğrenmesi mimarisine sınıflandırabiliriz:
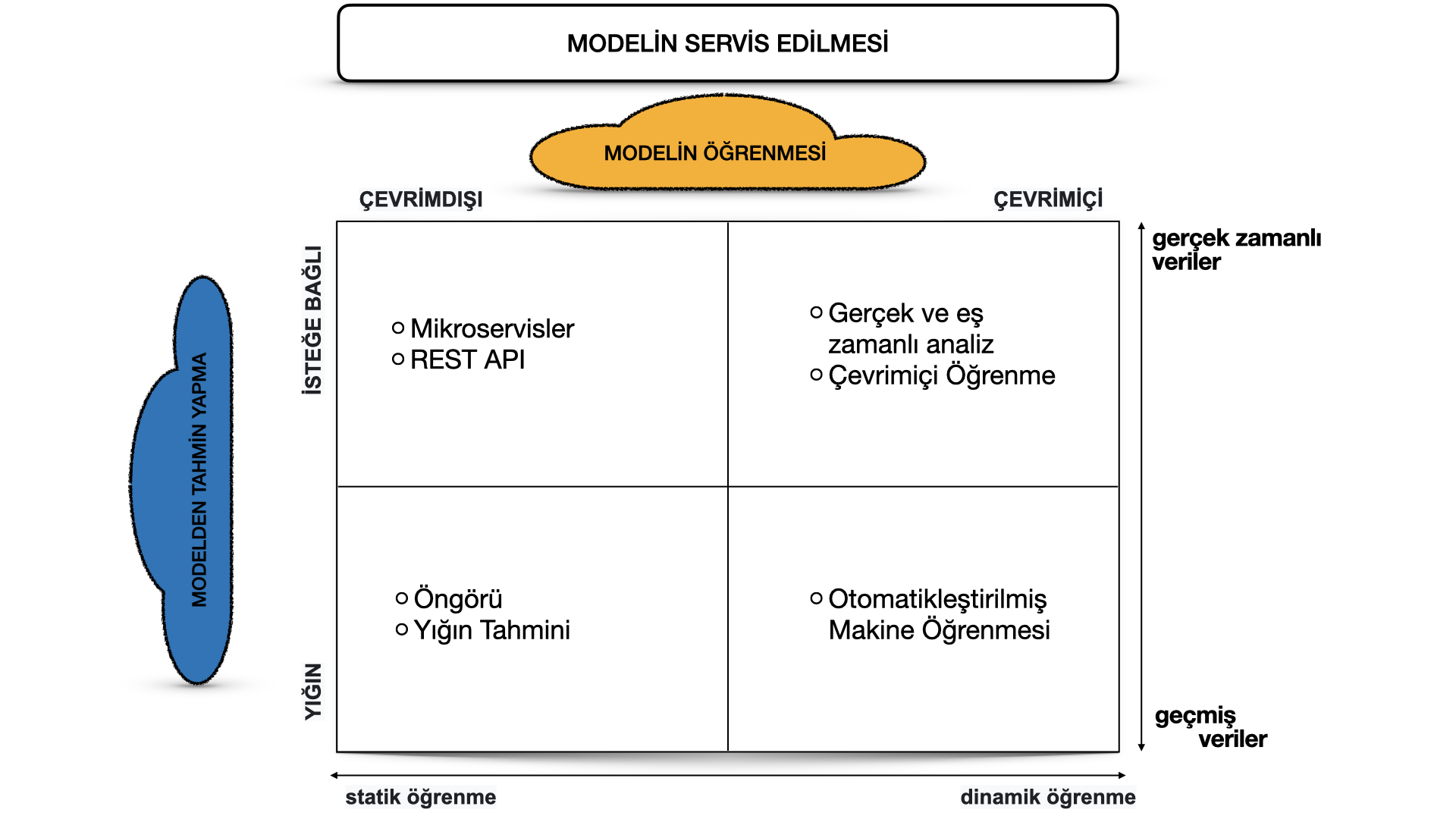
Aşağıda Tahmin (Öngörü), İnternet (Web) hizmeti, Çevrimiçi Öğrenme ve AutoML (Otomatikleştirilmiş Makine Öğrenmesi) gibi model mimari türlerinin açıklamasını sunuyoruz.
Tahmin (Öngörü)
Bu tür bir makine öğrenmesi iş akışı, akademik araştırmalarda veya veri bilimi eğitimlerinde (örneğin, Kaggle veya DataCamp) geniş çapta kullanılır. Bu form, bir makine öğrenmesi sistemi oluşturmanın en kolay yolu olduğundan bir kaç veri kullanarak makine öğrenmesi algoritmaları ile oynamak için kullanılır. Genellikle, mevcut bir veri kümesini alır, makine öğrenmesi modelini eğitiriz, ardından bu modeli başka (çoğunlukla geçmiş) veriler üzerinde çalıştırırız ve makine öğrenmesi modeli tahminlerde bulunur. Böylelikle bir öngörü elde ederiz. Bu tür makine öğrenmesi iş akışı çok kullanışlı değildir ve bu nedenle üretim sistemleri için (örneğin, mobil uygulamalara dağıtılsın diye) endüstriyel şirketlerde çok sık kullanılmaz.
İnternet (Web) hizmeti
Makine öğrenmesi modellerinin dağıtımı için en yaygın biçimde kullanılan mimari bir internet hizmetidir (mikroservis). Web hizmeti girdi verilerini alır ve bu girdi veri noktaları için bir tahmini geri verir. Model, geçmiş veriler üzerinde çevrimdışı olarak eğitilir, ancak tahminler üretmek için gerçek canlı verileri kullanır. Bir tahminden (yığın tahminler) farkı, bu makine öğrenmesi modelinin neredeyse gerçek zamanlı olarak çalışması ve tüm verileri bir kerede işlemek yerine tek bir kaydı tek seferde işlemesidir. Web hizmeti tahminler yapmak için gerçek zamanlı verileri kullanır, ancak yeniden eğitilene ve üretim ortamına yeniden dağıtılana kadar model sabittir, değişmez.
Aşağıdaki şekil, eğitilmiş modelleri dağıtılabilir hizmetler olarak sarmalamak için kullanılabilecek mimariyi göstermektedir. Dağıtım Stratejileri Bölümünde eğitilmiş makine öğrenmesi modellerini dağıtılabilir hizmetler olarak sarmalamak için kullanılabilecek yöntemlerini tartıştığımızı lütfen unutmayın.

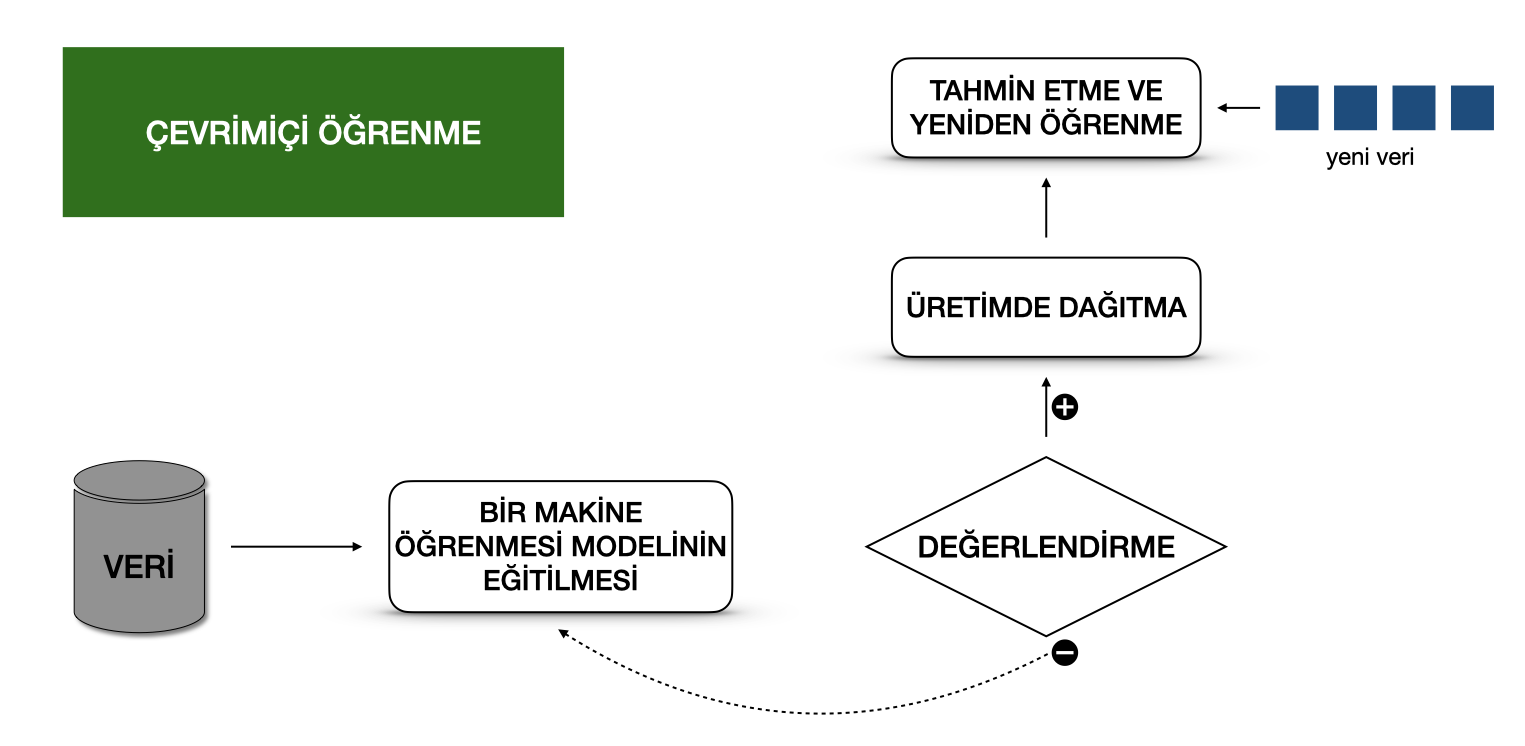
Çevrimiçi Öğrenme
Bir makine öğrenmesi modelini bir üretim sistemine yerleştirmenin en dinamik yolu, gerçek zamanlı akış analitiği (real-time streaming analytics) olarak da bilinen çevrimiçi öğrenmeyi uygulamaktır. Lütfen çevrimiçi öğrenmenin kafa karıştırıcı bir isim olabileceğini unutmayın çünkü bir makine öğrenmesi modelinin eğitimi genellikle canlı bir sistemde gerçekleştirilmez. Buna artımlı öğrenme (incremental learning) demeliyiz; ancak, çevrimiçi öğrenme terimi Makine Öğrenmesi camiaasında uzun süredir kullanılan oturmuş bir terimdir.
Bu tür bir makine öğrenmesi iş akışında, bir öğrenme algoritması, veri noktalarını tek tek veya mini-yığın olarak adlandırılan küçük gruplar halinde alacak şekilde sürekli bir veri akışına (data stream) sahiptir. Sistem, yeni veriler gelir gelmez anında bu verileri analiz eder, böylece makine öğrenmesi modeli yeni verilerle aşamalı olarak yeniden eğitilir. Bu sürekli olarak yeniden eğitilen model, bir web hizmeti olarak anında kullanılabilir.
Teknik olarak, bu tür bir makine öğrenmesi sistemi, büyük veri sistemlerinde lambda mimarisiyle (lambda architecture) iyi çalışır.
Genellikle, girdi verileri olayların bir akışıdır ve makine öğrenmesi modeli, verileri sisteme girerken alır, bu yeni veriler üzerinde tahminler sağlar ve daha sonra bu yeni verileri de kullanarak öğrenmeyi yeniden başlatır. Model tipik olarak bir Kubernetes kümesi veya benzeri bir sistem üzerinde bir servis olarak çalışır.
Üretimdeki bir çevrimiçi öğrenme sistemi ile ilgili büyük bir zorluk, sisteme kalitesiz veriler girerse, makine öğrenmesi modelinin yanı sıra tüm sistem performansının giderek azalacak olmasıdır.
AutoML
Çevrimiçi öğrenmenin daha da karmaşık bir sürümü, otomatikleştirilmiş makine öğrenmesi veya kısaca AutoML’dir.
AutoML büyük ilgi görmeye başladı ve kurumsal şirketlerde kullanılan Makine Öğrenmesi algoritmaları için bir sonraki büyük gelişme olarak kabul ediliyor. AutoML, makine öğrenmesi alanında herhangi bir uzmanlık olmadan minimum çabayla makine öğrenmesi modellerini eğitmeyi vaat ediyor. Kullanıcının sadece veri sağlaması gereklidir ve AutoML sistemi, sinir ağı mimarisi gibi bir makine öğrenmesi algoritmasını otomatik olarak seçer ve seçilen algoritmayı yapılandırır.
Modeli güncellemek yerine, üretim ortamında, anında yeni modellerle sonuçlanan eksiksiz bir Makine Öğrenmesi modeli eğitim hattını çalıştırırız. Şimdilik AutoML, makine öğrenmesi iş akışlarını uygulamanın çok deneysel bir yoludur. AutoML genellikle Google veya MS Azure gibi büyük bulut sağlayıcıları tarafından sağlanır. Bununla birlikte, AutoML ile oluşturulan modellerin gerçekten başarılı olması için gereken doğruluk düzeyine ulaşması gerekir.
Daha fazla okuma için
AutoML: Genel Bakış ve Araçlar
AutoML Karşılaştırması
Bir Makine Öğrenmesi modelini serileştirme formatları
Makine öğrenmesi modellerini dağıtmak için çeşitli formatlar vardır. Dağıtılabilir bir format elde etmek için, Makine Öğrenmesi modelinin mevcut olması ve bağımsız bir nesne olarak çalıştırılabilir olması gerekir. Örneğin, bir Spark işinde Scikit-learn modelini kullanmak isteyebiliriz. Bu, makine öğrenme modellerinin model eğitim ortamının dışında çalışması gerektiği anlamına gelir. Aşağıda, makine öğrenmesi modelleri için, kullanılan programlama dilinden bağımsız ve Tedarikçiye özgü değişim formatlarınından kısaca bahsedeceğiz.
Kullanılan programlama dilinden bağımsız değişim formatları
Birleştirme olarak Türkçe’ye çevrilebilecek olan Amalgamation yöntemi, bir makine öğrenmesi modelini dışa aktarmanın en basit yoludur. Model ve çalıştırılması gereken tüm kodlar tek bir paket olarak birleştirilmiştir. Genellikle, hemen hemen her platformda bağımsız bir program olarak derlenebilen tek bir kaynak kod dosyasıdır. Örneğin, SKompiler kullanarak bir Makine Öğrenmesi modelinin bağımsız bir versiyonunu oluşturabiliriz. Bu python paketi, eğitilmiş Scikit-learn modellerini, SQL sorguları, Excel formülleri, Portable Format for Analytics (PFA) dosyaları veya SymPy ifadeleri gibi diğer formlara dönüştürmek için bir araç sağlar. Sonuncusu, C, Javascript, Rust, Julia ve bunun gibi çeşitli programlama dillerinde çalıştırılabilecek koda çevrilebilir. Birleştirme (Amalgamation) basit bir kavramdır ve dışa aktarılan makine öğrenmesi modelleri taşınabilirdir. Lojistik regresyon veya karar ağacı gibi bazı kolay makine öğrenmesi algoritmaları için bu biçim kompakttır ve iyi bir performans gösterebilir, bu da kısıtlı gömülü ortamlar için çok kullanışlıdır. Ancak, bir makine öğrenmesi algoritmasına ait model kodunun ve bu modelin parametrelerinin birlikte yönetilmesi gerekir.
PMML, .pmml dosya uzantısına sahip XML tabanlı bir model servis formatıdır. PMML, Data Mining Group (DMG) tarafından standartlaştırılmıştır. Temel olarak .ppml dosya uzantısı, XML’de bir model ve iletim hattını tanımlar. PMML, tüm makine öğrenmesi algoritmalarını desteklemez ve açık kaynak odaklı araçlarda kullanımı lisans sorunları nedeniyle sınırlıdır.
PFA (Portable Format for Analytics), PMML’nin yerini alacak şekilde tasarlanmıştır. DMG’den: “Bir PFA belgesi, skorlama motoru adı verilen bir çalıştırılabilir dosyayı tanımlayan JSON biçimli bir metin dizisidir. Her motorun iyi tanımlanmış bir girdisi, iyi tanımlanmış bir çıktısı ve çıktıyı, ifade merkezli bir sözdizimi ağacında (syntax tree) oluşturmak için girdileri birleştiren fonksiyonları vardır.” (1) Koşul, döngü ve kullanıcı tanımlı fonksiyonlar gibi kontrol yapılarına sahiptir, (2) JSON içerisinde ifade edildiği için, bir PFA formatı, diğer programlar tarafından kolayca oluşturulabilir ve değiştirilebilir, (3) PFA, genişletilebilirlik geri çağırmaları (extensibility callbacks) destekleyen ayrıntılı bir fonksiyon kütüphanesine sahiptir. Makine Öğrenmesi modellerini PFA dosyaları olarak çalıştırmak için PFA’nın etkin olduğu bir ortama ihtiyacımız vardır.
ONNX (Open Neural Network eXchange), Makine Öğrenmesi modelinin elde edildiği programdan bağımsız bir dosya formatıdır. ONNX, herhangi bir makine öğrenmesi aracının tek bir model formatını paylaşmasına izin vermek için oluşturulmuştur. Bu format Microsoft, Facebook ve Amazon gibi birçok büyük teknoloji şirketi tarafından desteklenmektedir. Makine öğrenmesi modeli ONNX formatında serileştirildikten sonra, onnx-etkinleştirilmiş çalışma zamanı (runtime) kütüphaneleri (çıkarsama motorları da denir) tarafından tüketilebilir ve ardından tahminlerde bulunabilir.
Burada ONNX formatını kullanabilen araçların listesini bulacaksınız. Özellikle çoğu derin öğrenme aracının ONNX desteğine sahiptir.
Tedarikçiye özgü değişim formatları
Scikit-Learn, modelleri .pkl dosya uzantısıyla pickle‘lenmiş python nesneleri olarak kaydeder.
H2O, oluşturduğunuz modelleri POJO (Düz Eski Java Nesnesi - Plain Old Java Object) veya MOJO (Model Nesnesi, Optimize Edilmiş - Model Object, Optimized) formatlarına çevirmenize olanak tanır.
MLeap dosya biçiminde kaydedilebilen ve bir MLeap model sunucusu kullanılarak gerçek zamanlı olarak sunulabilen SparkML modelleri. MLeap çalışma zamanı, herhangi bir Java uygulamasında çalışabilen bir JAR’dır. MLeap, eğitime ait iletim hatları ve bu hatları bir MLeap Paketine aktarmak için Spark, Scikit-learn ve Tensorflow’u destekler. TensorFlow, modelleri .pb dosya uzantısıyla kaydeder; ki bu format, protokol tamponu (arabellek) dosyasının uzantısıdır (protocol buffer - protobuf).
PyTorch, patentli Torch Script’i kullanarak modelleri bir .pt dosyası olarak servis eder. PyTorch’un model formatı bir C– uygulamasından servis edilebilir.
Keras, bir modeli .h5 dosyası olarak kaydeder ve bu, bilim camiasında Hierarchical Data Format (Hiyerarşik Veri Biçimi - HDF)’ında kaydedilmiş bir veri dosyası olarak bilinir. Bu dosya türü çok boyutlu veri dizilerini içerir.
Apple, iOS uygulamalarında gömülü modelleri depolamak için .mlmodel uzantılı patentli dosya biçimine sahiptir. Apple’ın Core ML isimli kütüphanesi, Objective-C ve Swift programlama dillerini desteklemektedir. TensorFlow, Scikit-Learn gibi bir çok diğer makine öğrenmesi kütüphanesinde eğitilen uygulamalara ait makine öğrenmesi model dosyalarını iOS’ta kullanılmak üzere .mlmodel formatına çevirmek için coremltools ve Tensorflow Çeviricisi gibi araçlar kullanmanız gerekmektedir.
Aşağıdaki Tablo, tüm makine öğrenmesi modeli serileştirme formatlarını özetlemektedir:
| Açık Format | Tedarikçi | Dosya Uzantısı | Lisans | MÖ Araçları ve Platformları Desteği |
İnsan tarafından okunabilir |
Sıkıştırma | |
|---|---|---|---|---|---|---|---|
| “almagination (birleştirme)” | - | - | - | - | - | - | |
| PMML | DMG | .pmml | AGPL | R, Python, Spark | (XML) | ||
| PFA | DMG | JSON | PFA-enabled runtime | (JSON) | |||
| ONNX | SIG-LFAI | .onnx | TF, CNTK, Core ML, MXNet, ML.NET | - | |||
| TF Serving Formatı | .pf | TensorFlow | g-zip | ||||
| Pickle Formatı | .pkl | scikit-learn | g-zip | ||||
| JAR/ POJO | .jar | H2O | |||||
| HDF | .h5 | Keras | |||||
| MLEAP | .jar/ .zip | Spark, TF, scikit-learn | g-zip | ||||
| Torch Script | .pt | PyTorch | |||||
| Apple .mlmodel | Apple | .mlmodel | TensorFlow, scikit-learn, Core ML | - |
Daha fazla okuma için
MÖ Modelleri eğitim dosyası formatları
Açık Standart Modeller
Kod: Dağıtım İletim Hatları
Bir Makine öğrenmesi projesini servis etmenin son aşaması aşağıdaki üç adımı içerir:
- Modelin Servisi - Makine öğrenmesi modelini bir üretim ortamında dağıtma süreci.
- Modelin Performansını İzleme - Bir makine öğrenmesi modelinin performansını, tahmin veya öneri gibi canlı ve önceden görülmemiş verilere dayalı olarak gözlemleme süreci. Özellikle, önceki model performansından tahmin sapması gibi makine öğrenmesine özgü sinyallerle ilgileniyoruz. Bu sinyaller, modelin yeniden eğitilmesi için uyarıcılar olarak kullanılabilir.
- Modelin Performans Günlüğü - Her çıkarsama talebi bir günlük kaydı (log) ile sonuçlanır.
Aşağıda, Modeli Servis Etme Kalıplarını ve Model Dağıtım Stratejilerini tartışıyoruz.
Modeli Servis Etme Kalıpları
Bir üretim ortamında bir makine öğrenmesi modelini servis ederken üç bileşen dikkate alınmalıdır. Çıkarsama (inference), tahminleri hesaplamak için bir model tarafından alınacak verileri elde etme sürecidir. Bu süreç bir model, bu modeli çalıştırmak için bir yorumlayıcı ve girdi verileri gerektirir.
Bir makine öğrenmesi sistemini bir üretim ortamına dağıtmak için yapılması gereken iki şey vardır: ilki, otomatik yeniden eğitim ve makine öğrenmesi modelinin dağıtımı için iletim hattını dağıtmak. İkincisi, önceden görülmemiş veriler üzerinde tahmin elde etmek için bir API oluşturmak.
Modelin servis edilmesi, bir makine öğrenmesi modelini bir yazılım sistemine entegre etmenin bir yoludur. Bir makine öğrenmesi modelini üretime sokmak için kullanılabilecek beş tür kalıp arasındaki farkları aşağıda inceliyoruz: Servis-Olarak-Model (Model-as-Service), Bağımlılık-Olarak-Model (Model-as-Dependency), Önhesaplamalı (Precompute), İsteğe-Bağlı-Model (Model-on-Demand) ve Hibrit-Servis (Hybrid-Serving). Lütfen yukarıda açıklanan model serileştirme formatlarının herhangi bir model servis etme kalıbı için kullanılabileceğini unutmayın.
Aşağıdaki sınıflandırma bu yaklaşımları göstermektedir:

Şimdi, Servis-Olarak-Model, Bağımlılık-Olarak-Model, Önhesaplamalı, İsteğe-Bağlı-Model ve Hibrit-Servis gibi bir makine öğrenmesi modelini üretmeye yönelik kullanılabilecek servis etme kalıplarını göstereceğiz.
Servis-Olarak-Model
Servis-Olarak-Model, bir makine öğrenmesi modelini bağımsız bir servis olacak biçimde sarmalayarak gerçekleştirilen yaygın bir kalıptır. Makine öğrenmesi modelini ve yorumlayıcıyı, uygulamaların, bir REST API aracılığıyla istek gönderebileceği veya bir gRPC hizmeti olarak kullanabileceği özel bir web hizmeti içine alabiliriz. Bu kalıp, Tahmin, Web Hizmeti, Çevrimiçi Öğrenme gibi çeşitli makine öğrenmesi iş akışları için kullanılabilir.

Bağımlılık-Olarak-Model
Bağımlılık-Olarak-Model, bir makine öğrenmesi modelini paketlemenin muhtemelen en basit yoludur. Paketlenmiş bir ML modeli, yazılım uygulaması içinde bir bağımlılık (diğer bir deyişle destek dosyası - dependency) olarak kabul edilir. Örneğin uygulama, tahmin yöntemini çağırıp değerleri geri döndürerek bir makine öğrenmesi modelini geleneksel bir jar dosyası gibi kullanabilir. Bu tür bir yöntem uygulamasının döndürdüğü değer, önceden eğitilmiş bir makine öğrenmesi modeli tarafından gerçekleştirilen bazı tahminlerdir. Bağımlılık-Olarak-Model yaklaşımı çoğunlukla sadece Tahmin elde etmek için kullanılır.

Önhesaplamalı Servis
Bu tür bir makine öğrenmesi modeli hizmeti, Tahmin MÖ iş akışıyla sıkı bir şekilde ilişkilidir. Önhesaplamalı servis kalıbıyla, önceden eğitilmiş bir makine öğrenmesi modeli kullanır ve gelen veri yığını için tahminleri önceden hesaplarız. Elde edilen tahminler veritabanında saklanır. Bu nedenle, herhangi bir girdi isteği için, tahmin sonucunu almak üzere veritabanını sorgularız.

Daha fazla okuma için: Makine Öğrenmesini Üretime Getirme (Slaytlar)
İsteğe-Bağlı-Model
İsteğe-Bağlı-Model kalıbı, bir makine öğrenmesi modelini çalışma zamanında kullanılabilen bir bağımlılık olarak ele alır. Bu makine öğrenmesi modeli, Bağımlılık-Olarak-Model kalıbının aksine, kendi yayınlanma döngüsüne sahiptir ve bağımsız olarak yayınlanır.
Mesaj-aracı (message-broker) mimarisi genellikle bu tür isteğe-bağlı model servisi için kullanılır. Mesaj-aracı topoloji mimari kalıbı iki ana mimari bileşen türü içerir: bir aracı (broker) bileşeni ve bir olay işlemcisi (event processor) bileşeni. Aracı bileşeni, olay akışı (event flow) içinde kullanılan olay kanallarını (event channels) içeren merkezi kısımdır. Aracı bileşeninde bulunan olay kanalları mesaj kuyruklarıdır (message queues). Girdi ve çıktı kuyruklarıni içeren böyle bir mimariyi aklımızda canlandırabiliriz. Bir mesaj aracısı, bir işleme, tahmin isteklerini (prediction-requests) bir girdi kuyruğuna yazmasına izin verir. Olay işlemcisi, model servisi çalışma zamanını ve makine öğrenmesi modelini içerir. Bu işlemci aracıya bağlanır, bu istekleri toplu olarak kuyruktan okur ve tahminlerde bulunmak için bunları modele gönderir. Model servisi süreci, tahmin üretme servisini girdi verileri üzerinde çalıştırır ve sonuçlanan tahminleri çıktı kuyruğuna yazar. Daha sonra, kuyruğa alınmış tahmin sonuçları, tahmin talebini başlatan tahmin servisine gönderilir.

Daha fazla okuma için
Olay odaklı mimari
Gerçek zamanlı makine öğrenmesi uç noktaları için web hizmetleri ve akış karşılaştırması
Hibrit-Servis (Birleştirilmiş Öğrenme)
Hibrit servis olarak da bilinen Birleştirilmiş Öğrenme (Federe Öğrenme de denir - Federated Learning), kullanıcılara bir model servis etmenin başka bir yoludur. Yaptığı şekilde benzersizdir, çıktıyı tahmin eden tek bir model yoktur, aynı zamanda birçok model vardır. Bir sunucuda tutulan modele ek olarak, kullanıcılar kadar çok sayıda model vardır. Sunucudaki benzersiz bir model ile başlayalım. Sunucu tarafındaki model, gerçek dünya verileriyle yalnızca bir kez eğitilir. Her kullanıcı için başlangıç modelini olarak kabul edilir. Bu model nispeten daha genel olarak eğitilmiş bir modeldir, bu nedenle kullanıcıların çoğu için uygundur. Öte yandan, kullanıcı cihazında bulunan gerçek özgün modeller vardır. Mobil cihazlardaki artan donanım standartları nedeniyle cihazların kendi modellerini eğitmesi mümkündür. Yani, bu cihazlar kendi kullanıcıları için son derece özelleştirilmiş modellerini eğiteceklerdir. Arada bir, önceden eğitilmiş model verilerini (kişisel verileri değil) cihazlardan sunucuya gönderir. Sunucuda bulunan model bu yeni verilerle ayarlanacak, böylece tüm kullanıcı topluluğunun gerçek eğilimleri model tarafından ele alınacaktır. Tüm cihazlardan gelen model verileriyle bir daha ayarlanan sunucudaki model, tüm cihazların kullandığı yeni başlangıç modeli olacaktır. Kullanıcıların herhangi bir problem yaşamaması için, sunucu modelinin güncellenmesi, cihaz boştayken, WiFi’ye bağlıyken ve şarj olurken gerçekleşir. Ayrıca tüm test işlemleri cihazlar üzerinde yapılır, bu nedenle sunucudan alınan güncellenmiş model cihazlara gönderilir ve bu modelin işlevselliği cihazlar üzerinde test edilir.
Bu öğrenme türünün en büyük yararı, eğitim ve test için kullanılan ve son derece kişisel olan verilerin, kullanıcı hakkındaki mevcut tüm bilgiyi yakalarken hiçbir zaman cihazlardan dışarı çıkmamasıdır. Bu şekilde, bulutta tonlarca (muhtemelen kişisel) veri depolamak zorunda kalmadan yüksek doğrulukta modeller eğitmek mümkündür. Ancak bedava öğle yemeği (no free lunch) diye bir şey yoktur, normal makine öğrenmesi algoritmaları, her zaman eğitim için mevcut olan güçlü donanım üzerinde homojen ve büyük veri kümeleriyle oluşturulur. Federe Öğrenme ile başka koşullar da vardır, mobil cihazlar daha az güçlüdür, eğitim verileri milyonlarca cihaza dağıtılır ve bu cihazlar her zaman eğitim için müsait olmayabilir. Tam olarak bunun için TensorFlow Federated (TFF) oluşturulmuştur. TFF, Birleştirilmiş Öğrenme için oluşturulmuş hafif bir TensorFlow türüdür.

Dağıtım Stratejileri
Aşağıda, eğitilmiş modelleri dağıtılabilir hizmetler olarak sarmalamaya yönelik yaygın yöntemleri, yani makine öğrenmesi modellerini Docker Konteynerleri olarak Bulut Sunucularına (cloud instances) ve Sunucusuz Fonksiyonlar (serverless function) olarak dağıtmanın yaygın yollarını tartışıyoruz.
Makine Öğrenmesi Modellerini Docker Konteyner olarak Dağıtma
Günümüzde bir makine öğrenmesi modelinin dağıtımına yönelik standart, açık bir çözüm yoktur. Ancak, makine öğrenmesi modelinden yapılacak çıkarsama, herhangi bir durum ifadesi taşımadığından ve hafif ve idempotent olarak kabul edildiğinden, konteynerleştirme, ürünün teslimatı için fiili standart haline gelmiştir. Bu, bir makine öğrenmesi modelinin çıkarsama kodunu sarmalayan bir konteyner dağıtmamız gerektiği anlamına gelir. Şirket içi (on-premise), bulut veya hibrit dağıtımlar için Docker, fiili standart konteynerleştirme teknolojisi olarak kabul edilir.
Her zaman gerçekleştirebileceğiniz bir yol, tüm makine öğrenmesi teknoloji yığınını (destek dosyaları dahil) ve makine öğrenmesi modelinden tahmin yapan kodu bir Docker konteynerinde paketlemektir. Ardından, Kubernetes veya bir başka alternatifi (ör. AWS Fargate) gerekli düzenlemeleri (orchestration) gerçekleştirir. Tahmin elde etme gibi bir makine öğrenmesi modelinden elde edilecek fonksiyonellik, daha sonra bir REST API aracılığıyla kullanılabilir (örneğin, Flask uygulaması olarak gerçekleştirilebilir).

Makine Öğrenmesi Modellerini Sunucusuz Fonksiyonlar Olarak Dağıtma
Çeşitli bulut tedarikçileri halihazırda makine öğrenmesi platformları sağlamaktadır. Böylelikle modelinizi servisleriyle birlikte kolayca dağıtabilirsiniz. Amazon AWS Sagemaker, Google Cloud AI Platform, Azure Machine Learning Studio ve IBM Watson Machine Learning verilebilecek bazı örneklerdir. Ticari bulut hizmetleri, AWS Lambda ve Google App Engine servlet host gibi servisler kullanarak ML modellerinin konteynerleştirmesini de sağlar.
Bir makine öğrenmesi modelini sunucusuz bir fonksiyon (serverless function) olarak dağıtmak için, uygulama kodu (application code) ve bağımlılıklar (dependencies) tek bir giriş noktası fonksiyonu ile .zip dosyalarına paketlenir. Bu fonksiyon daha sonra Azure Functions, AWS Lambda veya Google Cloud Functions gibi büyük bulut sağlayıcıları tarafından yönetilebilir. Ancak, yapay olguların (artifacts) boyutu gibi dağıtılan yapay olguların (artifacts) olası kısıtlamalarına dikkat edilmelidir.

Bu çevirinin ve çevirideki grafiklerin izinsiz ve kaynak gösterilmeden kullanılması yasaktır.
Serinin diğer yazıları
- MLOps Serisi I - Baştan-Sona Makine Öğrenmesi İş Akışının Tanıtılması
- MLOps Serisi II - Burada çözmeye çalıştığımız iş sorunu nedir?
- MLOps Serisi III - Bir Makine Öğrenmesi Yazılımının Üç Aşaması