5 dakikada okunabilir.
MLOps Serisi I - Baştan-Sona Makine Öğrenmesi İş Akışının Tanıtılması
Bir makine öğrenmesi modelini elde etmek çoğu zaman kolay olabilir. Ancak bu modelin gerçek hayatta kullanılabilirliği ve üretimde (prodüksiyonda) son kullanıcıya sunulması zahmetli bir süreçtir.
Bu nedenle makine öğrenmesi ile ilgilenenler için MLOps (makine öğrenmesi operasyonları) isminde bir seri başlatıyorum. Her hafta MLOps ile ilgili İngilizce yazılmış çok başarılı bir internet günlüğünü Türkçe’ye çevirip paylaşacağım. Böylelikle bir makine öğrenmesi modelini servis ederken ve dağıtırken veya makine öğrenmesi tabanlı bir yazılım geliştirirken nelere dikkat edilmesi gerektiği ile MLOps ilkelerini ve alt yapısını daha iyi anlayabiliriz.
Serinin ilk çevirisi konuyla ilgili üst düzey bir tanıtım yapan Dr. Larysa Visengeriyeva, Anja Kammer, Isabel Bär, Alexander Kniesz, ve Michael Plöd tarafından INNOQ için yazılmış “An Overview of the End-to-End Machine Learning Workflow” isimli yazı.
MLOps sözcüğü makine öğrenmesi ve operasyon (operations) sözcüklerinin birleşimidir ve üretime (production) sokulan bir Makine Öğrenmesi (veya Derin Öğrenme) modelinin yaşam döngüsünü yönetmeye yardımcı olmak için veri bilimcileri ve operasyon uzmanları arasında iletişim ve işbirliği sağlayan bir uygulamadır. DevOps (Developer Operations - Geliştirici Operasyonları) veya DataOps (Data Operations - Veri Operasyonları)’na çok benzer. Naif bir bakış açısıyla, MLOps sadece makine öğrenmesi alanına uygulanan DevOps’tur.
Makine Öğrenmesi operasyonları, makine öğrenmesi modellerinin gelişimini daha güvenilir ve verimli yapmak için gerekli olan tüm süreçleri tanımlayarak makine öğrenmesi modellerinin geliştirilmesine ve dağıtımına (deployment) yardımcı olmak için gerekli ilkelerin belirlenmesi üzerine odaklanır.
Baştan-Sona Makine Öğrenmesi İş Akışının Tanıtılması
Bu bölümde, makine öğrenmesi tabanlı bir yazılım geliştirmek için gerçekleşmesi gereken tipik bir iş akışını üst düzey bir biçimde gözden geçireceğiz. Genel olarak, bir makine öğrenmesi projesinin hedefi toplanmış veriyi kullanarak ve bu veriye makine öğrenmesi algoritmalarını uygulayarak istatistiksel bir model elde etmektir. Bu nedenle, makine öğrenmesi tabanlı her yazılımın üç ana bileşeni vardır: Veri, bir makine öğrenmesi modeli ve kod. Tipik bir makine öğrenmesi iş akışı bu bileşenlere karşılık gelen üç ana aşamadan oluşmaktadır:
Veri Mühendisliği: veri toplama & veri hazırlama,
Makine Öğrenmesi Model Mühendisliği: bir makine öğrenmesi modelinin eğitilmesi & servis edilmesi, ve
Kod Mühendisliği: son ürüne elde edilen makine öğrenmesi modelinin entegre edilmesi.
Aşağıdaki şekil tipik bir makine öğrenmesi iş akışında olan temel adımları göstermektedir.
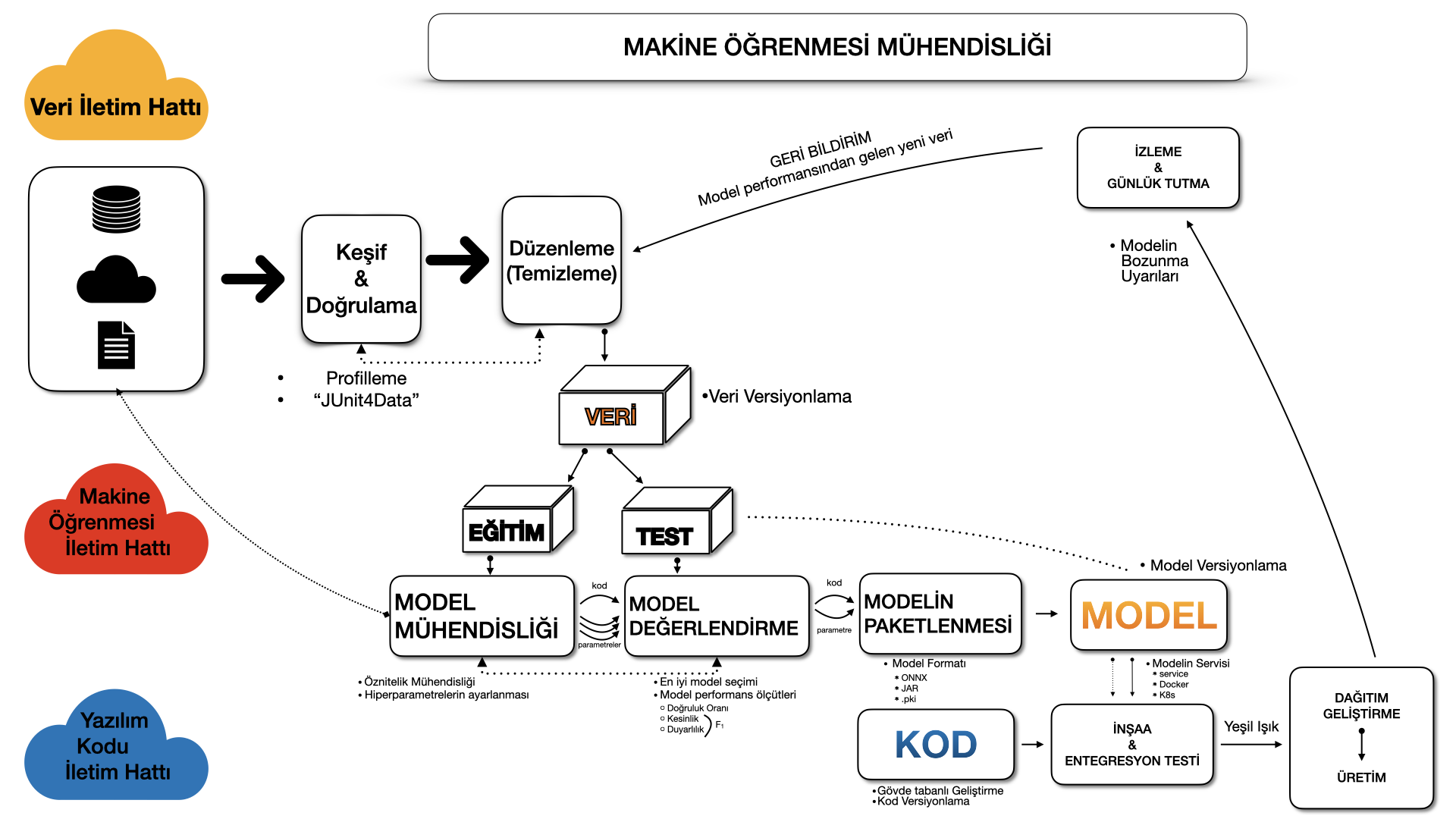
Veri Mühendisliği
Herhangi bir veri bilimi iş akışındaki ilk adım, analiz edilecek verinin elde edilmesi ve hazırlanmasıdır. Veriler çeşitli kaynaklardan alınır ve elde edilen bu veriler farklı formatlara sahip olabilir. Veri hazırlama (data preparation) aşaması, veri toplama (data acquisition) adımını takip eder ve Gartner’a göre “veri entegrasyonu, veri bilimi, veri keşfi ve analitik/iş zekası (business intelligence - BI) kullanım senaryoları için ham veriyi keşfetmek, birleştirmek, temizlemek ve işlenmiş bir veri setine dönüştürmek amacıyla kullanılan yinelemeli ve çevik bir süreçtir.” Veriyi analiz için hazırlama aşaması ara bir aşama olsa da, bu aşamanın kaynaklar ve zaman açısından çok masraflı olduğu bildirilmektedir. Veri hazırlama, veri bilimi iş akışındaki kritik bir işlemdir çünkü veride bulunan hataların bir sonraki aşama olan veri analizine aktarılmasını engellemek önem arz etmektedir. Böyle bir durum veriden yanlış çıkarsamaların elde edilmesiyle sonuçlanacaktır.
Bir Veri Mühendisliği iletim hattı (pipeline), makine öğrenmesi algoritmaları için gerekli eğitim ve test kümelerini sağlayacak olan mevcut veri üzerinde yapılacak bir takım operasyonlar dizisini kapsamaktadır:
- Veri Alınımı (Data Ingestion) - Spark, HDFS, CSV, vb. gibi çeşitli programlar ve formatlar kullanarak veri toplama. Bu adım, sentetik veri oluşturmayı veya veri zenginleştirmeyi (data enrichment) de içerebilir.
- Keşif ve Doğrulama (Exploration and Validation) - Verilerin içeriği ve yapısı hakkında bilgi almak için veri profili oluşturmayı içerir. Bu adımın çıktısı, maksimum, minimum, ortalama değer gibi istatistiklerin olduğu bir meta veri kümesidir. Veri doğrulama operasyonları, bazı hataları tespit etmek için veri setini tarayan, kullanıcı tanımlı hata tespit fonksiyonlarıdır.
- Veri Düzenleme (Temizleme) (Data Wrangling (Cleaning) ÇN: data munging de denir) - Verideki belirli nitelikleri (attributes) yeniden biçimlendirme ve verilerdeki hataları düzeltme süreci (örneğin, kayıp değer ataması).
- Veri Etiketleme (Data Labeling) - Her veri noktasının belirli bir kategoriye atandığı Veri Mühendisliği iletim hattının bir operasyonudur.
- Veri Ayırma (Data Splitting) - Bir makine öğrenmesi modeli elde etmek için temel makine öğrenmesi aşamaları sırasında kullanılmak üzere, mevcut veri kümesini eğitim, doğrulama ve test veri kümeleri olarak üçe parçalama.
Model Mühendisliği
Makine öğrenmesi iş akışının temeli, bir makine öğrenmesi modeli elde etmek için makine öğrenmesi algoritmalarını oluşturma ve bu algoritmaları çalıştırma aşamasıdır. Model Mühendisliği iletim hattı, sizi nihai bir modele götüren bir dizi operasyon içerir:
- Modelin Eğitilmesi (Model Training) - Bir makine öğrenmesi modelini eğitmek için bir makine öğrenmesi algoritmasını eğitim verilerine uygulama süreci. Ayrıca, modelin eğitimi için gerekli olan öznitelik mühendisliği (feature engineering) ve modelin hiperparametrelerini ayarlama adımlarını içerir.
- Modelin Değerlendirilmesi (Model Evaluation) - Bir makine öğrenmesi modelini üretimde (prodüksiyonda) son kullanıcıya sunmadan önce, bu modelin orijinal kodlanmış hedefleri karşıladığından emin olmak için eğitilmiş modelin doğrulanması.
- Modelin Test Edilmesi (Model Testing) - Eğitim ve doğrulama kümeleri dışında bulunan diğer tüm veri noktalarını kullanarak son “Model Kabul Testi”ni gerçekleştirme.
- Modeli Paketleme (Model Packaging) - Bir iş uygulaması tarafından kullanılsın diye, nihai makine öğrenmesi modelinin belirli bir formata (örneğin PMML, PFA veya ONNX) aktarılması işlemi.
Model Dağıtımı
Bir makine öğrenmesi modelini eğittikten sonra bu modeli bir mobil veya masaüstü uygulaması gibi bir iş uygulamasının parçası olarak dağıtmamız gerekir. Makine öğrenmesi modelleri, tahminler üretmek için çeşitli veri noktalarına (öznitelik vektörü) ihtiyaç duyar. Makine öğrenmesi iş akışının son aşaması, önceden tasarlanmış makine öğrenmesi modelinin mevcut yazılıma entegrasyonudur. Bu aşama aşağıdaki operasyonları içerir:
- Modelin Servis Edilmesi (İng. Model Serving) - Üretim (prodüksiyon) ortamında bir makine öğrenmesi modelinin yapısının ele alınması süreci.
- Modelin Performansını İzleme (İng. Model Performance Monitoring) - Bir makine öğrenmesi modelinin performansını, tahmin yaparak veya öneri sunarak canlı (İng. live) ve önceden görülmemiş verilere (İng. previously unseen data) dayalı olarak gözlemleme süreci. Özellikle, önceki modelin performansından tahmin sapması gibi makine öğrenmesine özgü göstergeler ile ilgileniyoruz. Bu göstergeler, modelin yeniden eğitilmesi için bize uyarı niteliğinde olabilir.
- Model Performansı Günlüğü (İng. Model Performance Logging) - Her çıkarım talebi günlük (İng. log) kaydı ile sonuçlanır.
Bu çevirinin ve çevirideki grafiklerin izinsiz ve kaynak gösterilmeden kullanılması yasaktır.
Serinin diğer yazıları
- MLOps Serisi I - Baştan-Sona Makine Öğrenmesi İş Akışının Tanıtılması
- MLOps Serisi II - Burada çözmeye çalıştığımız iş sorunu nedir?
- MLOps Serisi III - Bir Makine Öğrenmesi Yazılımının Üç Aşaması