40 dakikada okunabilir.
Önceden Eğitilmiş Visual Transformer (ViT) modeline İnce-Ayar Çekmek
Sıfırdan eğitim (training from scratch), bir modelin tamamen yeni bir görev için baştan sona eğitilmesini içerir. Bu, genellikle büyük veri setleri ve yüksek hesaplama gücü (computation power) gerektirir. Ayrıca, eğitim süreci genellikle günler veya haftalar sürebilir. Bu yöntem genellikle özel bir görev veya dil modeli oluşturmak isteyen araştırmacılar ve büyük şirketler tarafından kullanılır.
Ancak, bu işi hobi olarak yapan biri veya bir öğrenci için bir modeli sıfırdan oluşturmak o kadar kolay değildir. Büyük veri ve yüksek hesaplama gücünün yanında, aynı zamanda oluşturulacak modelin mimarisini (architecture) belirleme ve bu modele ait hiperparametreleri ayarlama (hyperparameter tuning) süreci de zorludur.
Bu sebeple, transfer öğrenme (transfer learning) adı verilen bir konsept literatürde yerini almıştır.
“Öğrenilenleri” bir problemden yeni ve farklı bir probleme uyarlamak Transfer Öğrenme fikrini temsil eder. Bir insanın öğrenmesi büyük ölçüde bu öğrenme yaklaşımına dayanmaktadır. Transfer öğrenimi sayesinde Java öğrenmek size oldukça kolay gelebilir çünkü öğrenme sürecine girildiğinde zaten programlama kavramlarını ve Python sözdizimini anlıyorsunuzdur.
Aynı mantık derin öğrenme (deep learning) için de geçerlidir. Transfer öğrenme, genellikle önceden-eğitilmiş (pre-trained) bir modelin (örneğin, Hugging Face tarafından sağlanan bir dil modeli) özel bir görev veya veri kümesine uyarlanmasıdır. Diğer bir deyişle, önceden eğitilmiş bir modelin ağırlıkları yeni veriler üzerinde eğitilir. Böylelikle, önceden eğitilmiş model yeni bir görev için hazır hale gelir.
Önceden eğitilmiş bir model kullanmanın önemli faydaları vardır. Hesaplama maliyetlerini ve karbon ayak izinizi azaltır ve sıfırdan eğitim gerçekleştirmenize gerek kalmadan son teknoloji ürünü modelleri kullanmanıza olanak tanır
🤗 Hugging Face’in transformers kütüphanesi çok çeşitli görevler için (örneğin, doğal dil işleme ve bilgisayarlı görü) önceden eğitilmiş binlerce modele erişim sağlar (https://huggingface.co/models). Önceden eğitilmiş bir model kullandığınızda, onu görevinize özel bir veri kümesi üzerinde eğitirsiniz. Bu, inanılmaz derecede güçlü bir eğitim tekniği olan ince-ayar (fine-tuning) olarak bilinir.
Transformer-tabanlı modeller genellikle görevden bağımsız gövde (task-independent body) ve göreve özel kafa (task-specific head) olarak ikiye ayrılır. Görevden bağımsız kısım genellikle Hugging Face tarafından sağlanan ağırlıklara (weights) sahiptir. Bu kısımdaki ağırlıklar dondurulmuştur ve herhangi bir güncellemeye (updates) sahip olmazlar. Göreve özel kafa’da, elinizdeki görev için ihtiyacınız kadar nöron oluşturulur ve sadece bu katmanda eğitim özel veri kümeniz kullanılarak gerçekleştirilir.

İnce-ayar, sinir ağının tamamında veya yalnızca katmanlarının bir alt kümesinde yapılabilir; bu durumda, ince ayarı yapılmayan katmanlar “dondurulur (frozen)” (geri yayılım (backpropagation) adımı sırasında güncellenmez).
İşte, bu tutorial’da özel bir veri kümesi (a custom dataset) için önceden eğitilmiş bir modele ince ayar yapacaksınız.
Google Colab’e Giriş
Burada gerçekleştireceğiniz analizleri GPU’ya sahip bir makinede yapmanızda fayda var. Çünkü kullanılacak ViT modeli ve veri kümesi oldukça büyük. Bu nedenle modele ince-ayar çekmek oldukça zaman alabilir.
Bu tutorial’da kullanılacak tüm Python kütüphanelerini aşağıdaki şekilde içe aktarma ile işe başlayalım:
from google.colab import drive
import os
import copy
import numpy as np
import pandas as pd
pd.set_option('display.max_columns', None)
import torch
from datasets import load_dataset, Image, load_from_disk
from transformers import (ViTFeatureExtractor,
ViTForImageClassification,
TrainingArguments,
TrainerCallback,
Trainer,
AutoModelForImageClassification,
AutoFeatureExtractor)
import evaluate
from huggingface_hub import notebook_login, create_repo
Tabii ki, bu kütüphaneler kişisel bilgisayarınızda veya Colab ortamınızda yüklü değilse, öncelikle bunları yüklemeniz (install) gerekmektedir:
!pip3 install datasets
!pip install transformers
!pip install transformers[torch]
!pip install accelerate -U
!pip install evaluate
!pip install scikit-learn
Gerekli kütüphaneler yüklendikten ve bu kütüphaneler Python ortamına içeri aktarıldıktan sonra, yapmanız gereken işlem Depolama (Storage) alanını ayarlamaktır.
Google Colab’in bir faydası, Google Drive’ınıza bağlanmanıza olanak sağlamasıdr. Böylelikle, elinizdeki veriyi Drive’da barındırırken, kodlarınızı GPU destekli bir Jupyter Not Defterinde çalıştırabilirsiniz.
Şimdi Google Drive’ı Colab’a bağlayalım. Google Drive’ınızın tamamını Colab’a bağlamak için google.colab kütüphanesindeki drive modülünü kullanabilirsiniz:
drive.mount('/content/gdrive')


Google Hesabınıza erişim izni verdikten sonra Drive’a bağlanabilirsiniz.
Drive bağlandıktan sonra "Mounted at /content/gdrive" mesajını alırsınız ve dosya gezgini bölmesinden Drive’ınızın içeriğine göz atabilirsiniz.
Şimdi, Google Colab’in çalışma dizinini (working directory) kontrol edelim:
!pwd
# /content
Daha sonra Python’un yerleşik (built-in) kütüphanelerinden olan os kütüphanesini kullanarak project isimli klasörü Drive’da yaratalım.
path = "./gdrive/MyDrive/project"
os.mkdir(path)
Artık project klasörüne yarattığımıza göre, geçerli çalışma dizinini (current working directory) bu klasör olarak değiştirelim:
os.chdir('./gdrive/MyDrive/project')
Artık gerçekleştireceğimiz tüm işlemler bu dizin altında yapılacak, kaydedilecek tüm dosyalar bu dizin altında kaydedilecektir.
Veri Kümesi
Bilgisayar kullanımıyla hastalıkların otomatik tespiti önemli ancak henüz keşfedilmemiş bir araştırma alanıdır. Bu tür yenilikler tüm dünyada tıbbi uygulamaları iyileştirebilir ve sağlık bakım sistemlerini iyileştirebilir. Bununla birlikte, tıbbi görüntüleri içeren veri kümeleri neredeyse hiç mevcut değildir, bu da yaklaşımların tekrarlanabilirliğini ve karşılaştırılmasını neredeyse imkansız hale getirmektedir.
Bu nedenle burada, tıp doktorları (deneyimli endoskopistler) tarafından etiketlenmiş ve doğrulanmış, gastrointestinal (gastrointestinal) sistemin içinden görüntülerden oluşan Kvasir veri kümesinin 2. versiyonunu (kvasir-dataset-v2) kullanacağız.
Kvasir veri kümesi yaklaşık 2.3GB büyüklüğündedir ve yalnızca araştırma ve eğitim amaçlı kullanılmak suretiyle ücretsizdir: https://datasets.simula.no/kvasir/
Veri kümesi, her biri 1.000 görüntüye sahip olan 8 sınıftan, yani toplam 8.000 görüntüden oluşmaktadır.

Görüntülerden oluşan bu koleksiyon, üç önemli anatomik işareti ve üç klinik açıdan önemli bulgu halinde sınıflandırılmıştır. Ayrıca endoskopik polip çıkarılmasıyla ilgili iki kategoride görüntü içermektedir.
Anatomik işaretler arasında z-çizgisi (z-line), pilor (pylorus), çekum(çecum) bulunurken patolojik bulgu özofajit (esophagitis), polipler (polyps), ülseratif kolit (ulcerative colitis) içermektedir. Ek olarak, lezyonların çıkarılmasıyla ilgili çeşitli görüntüler de sunulmaktadur; örneğin boyalı ve kaldırılmış polipler (dyed and lifted polyps), boyalı rezeksiyon kenarları (dyed resection margins).
JPEG görüntüleri ait oldukları sınıfa göre adlandırılan ayrı klasörlerde saklanmaktadır.
Veri seti, $720 \times 576$’dan $1920 \times 1072$ piksele kadar farklı çözünürlükteki görüntülerden oluşur ve içeriğe göre adlandırılmış ayrı klasörlerde saklanacak şekilde düzenlenmiştir.
Şimdi yukarıdaki websayfasında bulunan ve görüntüleri içeren kvasir-dataset-v2.zip isimli zip dosyasını wget komutu ile project dizinine indirelim:
!wget https://datasets.simula.no/downloads/kvasir/kvasir-dataset-v2.zip
# --2023-10-04 08:44:25-- https://datasets.simula.no/downloads/kvasir/kvasir-dataset-v2.zip
# Resolving datasets.simula.no (datasets.simula.no)... 128.39.36.14
# Connecting to datasets.simula.no (datasets.simula.no)|128.39.36.14|:443... connected.
# HTTP request sent, awaiting response... 200 OK
# Length: 2489312085 (2.3G) [application/zip]
# Saving to: ‘kvasir-dataset-v2.zip’
#
# kvasir-dataset-v2.z 100%[===================>] 2.32G 14.4MB/s in 2m 34s
#
# 2023-10-04 08:47:00 (15.4 MB/s) - ‘kvasir-dataset-v2.zip’ saved [2489312085/2489312085]
İndirme tamamlandıktan sonra, bu zip dosyasını unzip’leyelim ve görüntü verilerimizi elde edelim:
!unzip kvasir-dataset-v2.zip
Bu işlemden sonra project klasörünün altında kvasir-dataset-v2 isimli yeni bir klasör oluşacaktır.
zip dosyasıyla işimiz bittiği için yer kaplamaması için rm komutu ile silelim:
!rm -rf kvasir-dataset-v2.zip
Daha sonra, os kütüphanesini kullanarak, kolaylık olması açısından kvasir-dataset-v2 isimli dosyayı image_data olarak yeniden isimlendirelim:
os.rename('kvasir-dataset-v2', 'image_data')
Son durumda görüntülerden oluşan veri kümesi yapısı (dataset structure) şu şekilde olacaktır:
image_data/dyed-lifted-polyps/0a7bdce4-ac0d-44ef-93ee-92dfc8fe0b81.jpg
image_data/dyed-lifted-polyps/0a7ece5b-caaa-496e-9e6e-0c7eab171527.jpg
...
image_data/dyed-resection-margins/0a0b455d-d3dd-4be4-a6a3-90f81d8c8f36.jpg
image_data/dyed-resection-margins/0a2a2f35-c798-447c-a883-8f2f448bfe07.jpg
...
image_data/ulcerative-colitis/00a436bc-67ee-4a43-b1a7-25130a2d4e72.jpg
image_data/ulcerative-colitis/cat/0aacb7fa-19fb-4bd6-9a43-3c0a246e7a58.jpg
Bu özel (custom) veri kümesini HuggingFace ortamına yüklemek üzere bir veri kümesinin yapısını (structure) ve içeriğini (content) değiştirmek için birçok araç sağlayan Hugging Face’in datasets modülündeki load_dataset fonksiyonunu kullanabilirsiniz. Bu fonksiyon ya Dataset ya da DatasetDict döndürecektir:
full_dataset = load_dataset("imagefolder", data_dir="./image_data", split="train")
full_dataset
# Dataset({
# features: ['image', 'label'],
# num_rows: 8000
# })
Veri kümesinde 8,000 görüntü olduğunu ve görüntülerin etiketlerinin (label) otomatik oluşturulduğunu kolaylıkla görebilirsiniz.
full_dataset.features
# {'image': Image(decode=True, id=None),
# 'label': ClassLabel(names=['dyed-lifted-polyps', 'dyed-resection-margins', 'esophagitis', 'normal-cecum', 'normal-pylorus', 'normal-z-line', 'polyps', 'ulcerative-colitis'], id=None)}
Bu bir sözlüktür (dictionary). label anahtarını kullanarak kolaylıkla etiketleri (labels) çekebilirsiniz:
labels = full_dataset.features['label']
labels
# ClassLabel(names=['dyed-lifted-polyps', 'dyed-resection-margins', 'esophagitis', 'normal-cecum', 'normal-pylorus', 'normal-z-line', 'polyps', 'ulcerative-colitis'], id=None)
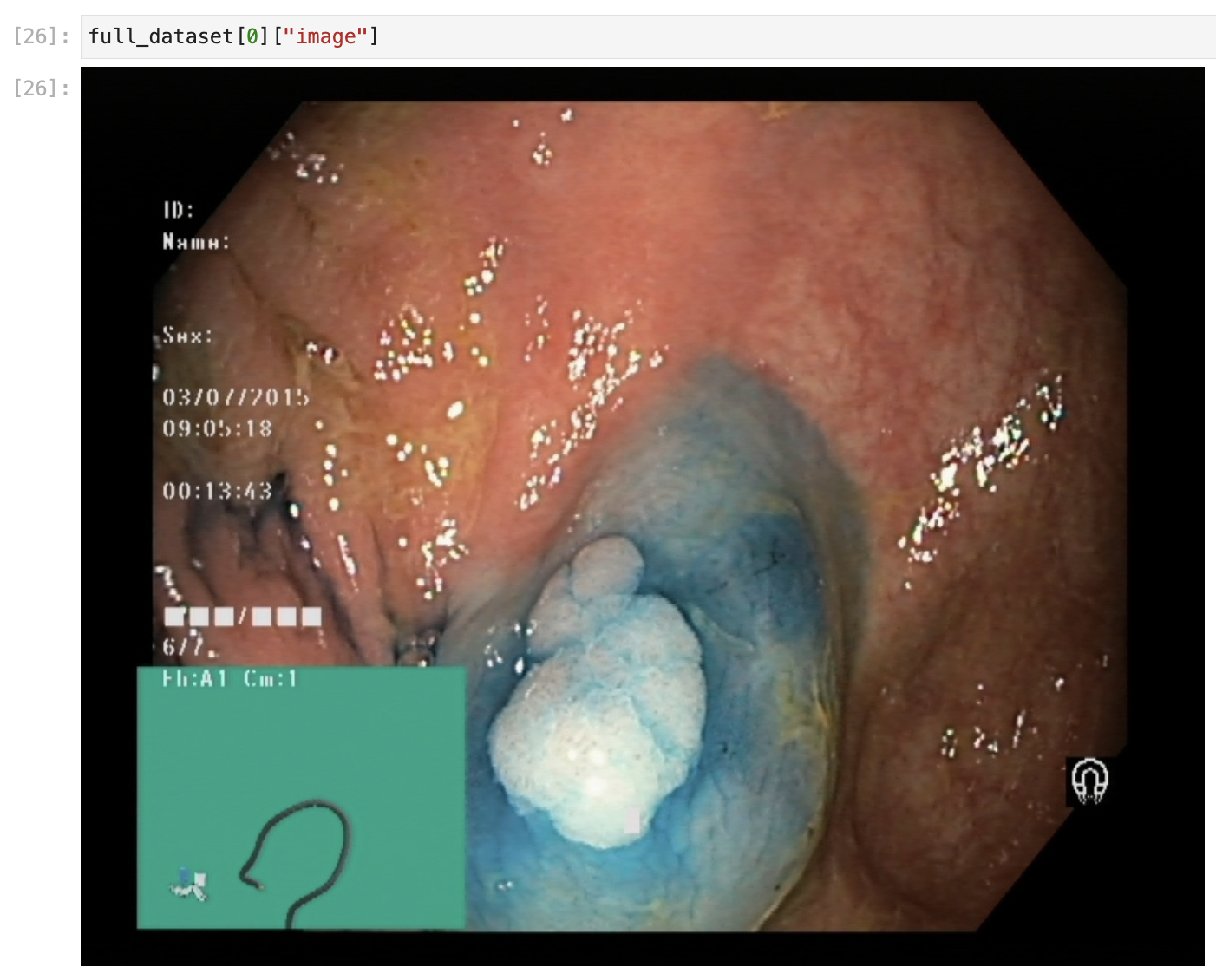
Spesifik bir görüntüye ulaşmak da oldukça kolaydır. Yapmanız gereken bir indeks kullanmaktır. Şimdi veri kümesindeki ilk görüntüye ulaşalım:
full_dataset[0]
# {'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=720x576>,
# 'label': 0}
Görüldüğü üzere, etiketlere otomatik olarak tamsayı atanmıştır. Burada 0 tamsayısına sahip etiketin ismi dyed-lifted-polyps‘dır.
full_dataset[0]['label'], labels.names[full_dataset[0]['label']]
# (0, 'dyed-lifted-polyps')
Bu görüntününün moduna ve etiketine de kolaylıkla erişilebilir:
full_dataset[0]['image'].mode
# 'RGB
Şimdi etiketler ve bu etiketlere ait id’leri (numaraları) içerisinde tutan iki sözlük (dictionary) oluşturalım:
id2label = {str(i): label for i, label in enumerate(labels.names)}
print(id2label)
# {'0': 'dyed-lifted-polyps', '1': 'dyed-resection-margins', '2': 'esophagitis', '3': 'normal-cecum', '4': 'normal-pylorus', '5': 'normal-z-line', '6': 'polyps', '7': 'ulcerative-colitis'}
label2id = {v: k for k, v in id2label.items()}
print(label2id)
# {'dyed-lifted-polyps': '0', 'dyed-resection-margins': '1', 'esophagitis': '2', 'normal-cecum': '3', 'normal-pylorus': '4', 'normal-z-line': '5', 'polyps': '6', 'ulcerative-colitis': '7'}
Bu iki sözlüğü daha sonra kullanacağız.
datasets modülünde bulunan Image fonksiyonu, bir görüntü nesnesini döndürmek için image sütunundaki verilerin kodunu otomatik olarak çözer. Şimdi görselin ne olduğunu görmek için image sütununu çağırmayı deneyiniz:
full_dataset[0]["image"]
full_dataset[1000]["image"]
Model
Burada görüntü sınıflandırma (image classification) görevini gerçekleştireceğiz. Veri kümesinde 8 farklı sınıf var. Bu nedenle çok-sınıflı sınıflandırma (multi-class classification) problemi ile karşı karşıyayız.
Çok-sınıflı görüntü sınıflandırma problemi için önceden-eğitilmiş (pre-trained) bir modele ihtiyacımız var. HuggingFace Hub’da görüntü sınıflandırma için oldukça fazla önceden-eğitilmiş model bulabilirsiniz - https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads&library=pytorch
Görüntü sınıflandırma için transfer öğrenmenin arkasındaki sezgi, eğer bir model yeterince geniş ve genel bir veri kümesi üzerinde eğitilirse, bu model etkili bir şekilde görsel dünyanın genel bir modeli olarak hizmet edebilir. Daha sonra büyük bir modeli büyük bir veri kümesi üzerinde eğiterek sıfırdan başlamanıza gerek kalmadan bu öğrenilen özellik haritalarından (feature maps) yararlanabilirsiniz.
Birçok görevde kullanabileceğiniz bu yaklaşım, hedeflenen verileri kullanarak bir modeli sıfırdan eğitmekten daha iyi sonuçlar vermektedir.
Artık ihtiyaçlarımıza uyacak şekilde ince ayar yapacağımız temel modelimizi seçebiliriz.
Burada Visual Transformer (ViT) denilen bir görsel transformer modelini kullanacağız (https://huggingface.co/google/vit-base-patch16-224).
ViT, “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” isimli makalede 2021 yılında Dosovitskiy ve arkadaşları tarafından tanıtılmıştır. ViT modeli ImageNet-21k (14 milyon görüntü, 21.843 sınıf) veri kümesi üzerinde önceden eğitilmiş ve ImageNet 2012 (1 milyon görüntü, 1.000 sınıf) veri kümesi üzerinde ince ayar çekilmiştir. Girdi görüntüleri $224 x 224$ çözünürlüğe sahiptir. Genel olarak üç tür ViT modeli vardır:
- ViT-base: 12 katmana, 768 gizli boyuta ve toplam 86M parametreye sahiptir.
- ViT-large: 24 katmana, 1024 gizli boyuta ve toplam 307M parametreye sahiptir.
- ViT-huge: 32 katmanı, 1280 gizli boyutu ve toplam 632M parametresi vardır.

Bu tutorial için Hugging Face’te bulunan the google/vit-base-patch16-224-in21k model modelini kullanacağız.
İlk olarak biraz veri temizliği yapalım ve RGB olmayan (tek kanallı, gri tonlamalı) görüntüleri veri kümesinden kaldıralım:
# Remove from dataset images which are non-RGB (single-channel, grayscale)
condition = lambda data: data['image'].mode == 'RGB'
full_dataset = full_dataset.filter(condition)
full_dataset
# Dataset({
# features: ['image', 'label'],
# num_rows: 8000
# })
Görüntülerin hepsi üç kanallı, yani RGB modundadır. Bu nedenle herhangi bir filtreleme işlemi gerçekleşmemiştir.
Veri kümesini eğitim/test olarak parçalamak
Modeli seçtiğimizde göre ilk olarak yapmamız gereken veri kümesini eğitim (train) ve test olacak şekilde ikiye parçalamak (splitting). Bunun için Hugging Face’in train_test_split() fonksiyonunu(https://huggingface.co/docs/datasets/v2.14.5/en/package_reference/main_classes#datasets.Dataset.train_test_split) kullanabilir ve parçalanmanın (splitting) boyutunu belirlemek için test_size argümanı belirtebilirsiniz. Burada test kümesinin büyüklüğünü belirlemek için test_size argümanının değeri olarak %15 kullanıyoruz, yani, 6800 görüntü, modeli eğitmek için, geri kalan 1200 görüntü, modeli test etmek için kullanılacaktır.
dataset = full_dataset.shuffle().train_test_split(test_size=0.15, stratify_by_column = 'label')
dataset
# DatasetDict({
# train: Dataset({
# features: ['image', 'label'],
# num_rows: 6800
# })
# test: Dataset({
# features: ['image', 'label'],
# num_rows: 1200
# })
# })
Kolaylıkla anlaşılacağı üzere bir DatasetDict nesnesine sahibiz artık. Bu bir sözlüktür. Anahtarları (keys) train ve test‘tir. Bu anahtarlardaki değerleri (yani, veri kümelerini) ayrı ayrı değişkenlere atayalım:
train_dataset = dataset["train"]
train_dataset
# Dataset({
# features: ['image', 'label'],
# num_rows: 6800
# })
test_dataset = dataset["test"]
test_dataset
# Dataset({
# features: ['image', 'label'],
# num_rows: 1200
# })
Öznitelik Çıkarıcı
Vision Transformer modeli temel olarak iki önemli bileşenden oluşur: bir sınıflandırıcı (classifier) ve bir öznitelik çıkarıcı (feature extractor).
ViT modelini kullanarak sınıflandırma gerçekleştirmeden önce Öznitelik Çıkarıcı (Feature Extractor) adı verilen bir işlem gerçekleştirmeliyiz.
Öznitelik çıkarsama, ses veya görüntü modelleri için girdi özniteliklerinin (input features) hazırlanmasından sorumludur. Bu öznitelik çıkarsama adımını, Doğal Dil İşleme (Natural Language Processing) görevlerindeki Token’laştırma (Tokenizer) adımı olarak düşünebilirsiniz.
Öznitelik çıkarsama, elimizdeki görüntüleri normalleştirmek (normalizing), yeniden boyutlandırmak (resizing) ve yeniden ölçeklendirmek (rescaling) üzere, görüntülerin “piksel değerlerinin” tensörlerine ön-işleme gerçekleştirmek için kullanılır.
ViT modeline ait Feature Extractor’ı Hugging Face’in transformers kütüphanesinden şu şekilde başlatıyoruz:
# modeli içe aktar
model_name = 'google/vit-base-patch16-224-in21k'
feature_extractor = ViTFeatureExtractor.from_pretrained(model_name)
feature_extractor
# ViTFeatureExtractor {
# "do_normalize": true,
# "do_rescale": true,
# "do_resize": true,
# "image_mean": [
# 0.5,
# 0.5,
# 0.5
# ],
# "image_processor_type": "ViTFeatureExtractor",
# "image_std": [
# 0.5,
# 0.5,
# 0.5
# ],
# "resample": 2,
# "rescale_factor": 0.00392156862745098,
# "size": {
# "height": 224,
# "width": 224
# }
# }
Öznitelik çıkarıcıya ait yapılandırma (configuration), normalleştirme, ölçekleme ve yeniden boyutlandırmanın true olarak ayarlandığını göstermektedir.
Sırasıyla image_mean ve image_stdde saklanan ortalama ve standart sapma değerleri kullanılarak üç renk kanalında (Red Green Blue - RGB) normalleştirme gerçekleştirilir.
Çıktı boyutu size anahtarı ile $224 \times 224$ piksel olarak ayarlanır.
Öznitelik çıkarıcıyla işlemeyi tek bir görüntü üzerinde şu şekilde gerçekleştiririz:
example = feature_extractor(train_dataset[0]['image'], return_tensors='pt')
example
# {'pixel_values': tensor([[[[-0.9608, -0.9608, -0.9608, ..., -0.9608, -0.9608, -0.9686],
# [-0.9686, -0.9608, -0.9608, ..., -0.9608, -0.9686, -0.9686],
# [-0.9686, -0.9608, -0.9686, ..., -0.9686, -0.9686, -0.9765],
# ...,
# [-0.9843, -0.9843, -0.9843, ..., -0.9843, -0.9843, -0.9843],
# [-0.9843, -0.9843, -0.9843, ..., -0.9843, -0.9843, -0.9843],
# [-0.9843, -0.9843, -0.9843, ..., -0.9843, -0.9843, -0.9843]],
#
# [[-0.9608, -0.9608, -0.9529, ..., -0.9608, -0.9608, -0.9686],
# [-0.9686, -0.9608, -0.9608, ..., -0.9608, -0.9686, -0.9686],
# [-0.9686, -0.9608, -0.9686, ..., -0.9686, -0.9686, -0.9686],
# ...,
# [-0.9843, -0.9843, -0.9843, ..., -0.9843, -0.9843, -0.9843],
# [-0.9843, -0.9843, -0.9843, ..., -0.9843, -0.9843, -0.9843],
# [-0.9843, -0.9843, -0.9843, ..., -0.9843, -0.9843, -0.9843]],
#
# [[-0.9686, -0.9608, -0.9608, ..., -0.9686, -0.9608, -0.9765],
# [-0.9686, -0.9686, -0.9686, ..., -0.9686, -0.9686, -0.9686],
# [-0.9686, -0.9765, -0.9765, ..., -0.9686, -0.9686, -0.9686],
# ...,
# [-0.9843, -0.9843, -0.9843, ..., -0.9922, -0.9922, -0.9843],
# [-0.9843, -0.9843, -0.9843, ..., -0.9922, -0.9843, -0.9843],
# [-0.9843, -0.9843, -0.9843, ..., -0.9922, -0.9843, -0.9843]]]])}
Oluşacak tensörün boyutu şu şekildedir:
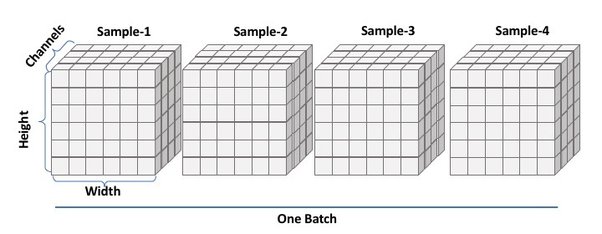
example['pixel_values'].shape
Kolaylıkla anlaşılacağı üzere, ön-işleme adımından sonra 4 boyutlu bir tensör elde edilmektedir. Burada ilk boyut (dimension) yığın büyüklüğünü (batch size), ikinci boyut görüntülerdeki kanal sayısını (number of channels, RGB görüntüler ile çalıştığımız için üç kanal var), üçüncü ve dördüncü boyutlar, sırasıyla görüntülerin yüksekliğini (height) ve genişliğini (width) temsil etmektedir.
Burada not edilmesi gereken diğer bir durum pixel_values anahtarının sahip olduğu değerin, modelin beklediği temel girdi olmasıdır.
Bu ön-işleme adımını tüm veri kümesine daha verimli bir şekilde uygulamak için, preprocess adı verilen bir fonksiyon oluşturalım ve dönüşümleri map yöntemini kullanarak gerçekleştirelim:
def preprocess(examples):
# take a list of PIL images and turn them to pixel values
inputs = feature_extractor(examples['image'], return_tensors='pt')
# include the labels
inputs['label'] = examples['label']
return inputs
# apply to train-test datasets
prepared_train = train_dataset.map(preprocess, batched=True)
prepared_test = test_dataset.map(preprocess, batched=True)
prepared_train
# Dataset({
# features: ['image', 'label', 'pixel_values'],
# num_rows: 6800
# })
prepared_test
# Dataset({
# features: ['image', 'label', 'pixel_values'],
# num_rows: 1200
# })
Kolaylıkla görülebileceği üzere eğitim ve test kümelerinde artık 'pixel_values' isimli yeni bir özniteliğe sahibiz.
EK NOT
Ön-işleme (pre-processing) çok zaman alabilir. Özellikle not defterinin (notebook) tamamını tekrar tekrar çalıştırmanız gerektiğinde.
Bunu önlemek için veri kümelerinizi (eğitim ve test veri kümeleri) ön-işleme tabi tuttuktan sonra diske kaydedin ve tekrar kullanmanız gerektiğinde bu ön-işlenmiş kümeleri tekrar yükleyin.
Bu nedenle ilk olarak, ön-işlemeden geçirilmiş eğitim ve test kümelerinin saklanacağı klasörleri çalışma dizinimizde (yani ./model) yaratalım. Burada, eğitim ve test kümeleri için ayrı dosyalar oluşturuyoruz çünkü Hugging Face bu veri kümelerini shard’lara ayırdıktan sonra diske kaydetme işlemi yapmaktadır:
os.makedirs('./prepared_datasets/train')
os.makedirs('./prepared_datasets/test')
prepared_train.save_to_disk("./prepared_datasets/train")
prepared_test.save_to_disk("./prepared_datasets/test")
Artık ihtiyacımız olduğunda kaydettiğimiz bu ön-işlenmiş veri kümelerini tekrar geri yükleyip işlerimize devam edebiliriz:
prepared_train = load_from_disk("./prepared_datasets/train")
prepared_test = load_from_disk("./prepared_datasets/test")
ViT’i yüklemek
Elimizdeki görüntüleri kullanacağımız modelin istediği uygun formata biçimlendirdikten sonra, bir sonraki adım ViT’yi indirip başlatmaktır (initialize).
Burada da, öznitelik çıkarıcıyı (feature extractor) yüklemek (load) için kullandığımız from_pretrained yöntemiyle Hugging Face’in transformers kütüphanesini kullanıyoruz.
num_classes = prepared_train.features["label"].num_classes
# 8
model = ViTForImageClassification.from_pretrained(model_name,
num_labels = num_classes,
label2id = label2id,
id2label = id2label)
#Some weights of ViTForImageClassification were not initialized from the model checkpoint at google/vit-base-patch16-224-in21k and are newly initialized: ['classifier.weight', 'classifier.bias']
#You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Sınıflandırma için ViT’ye ince-ayar çektiğimiz için ViTForImageClassification sınıfını kullanıyoruz. Varsayılan olarak bu, yalnızca iki çıktıya sahip bir sınıflandırma başı (classification head) ile modeli başlatır.
Elimizdeki özel veri kümesinde 8 farklı sınıf var, dolayısıyla 8 çıktı ile modeli başlatmak istediğimizi belirtmek isteriz. Bunu, num_labels argümanıyla gerçekleştiririz.
Model mimarisinden anlaşılacağı üzere, ViT model 12 adet kodlayıcıdan (encoder) oluşmaktadır. Son katman 8 gizli birime (hidden unit, yani nöron) sahip sınıflandırma katmanıdır.
model
# ViTForImageClassification(
# (vit): ViTModel(
# (embeddings): ViTEmbeddings(
# (patch_embeddings): ViTPatchEmbeddings(
# (projection): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
# )
# (dropout): Dropout(p=0.0, inplace=False)
# )
# (encoder): ViTEncoder(
# (layer): ModuleList(
# (0-11): 12 x ViTLayer(
# (attention): ViTAttention(
# (attention): ViTSelfAttention(
# (query): Linear(in_features=768, out_features=768, bias=True)
# (key): Linear(in_features=768, out_features=768, bias=True)
# (value): Linear(in_features=768, out_features=768, bias=True)
# (dropout): Dropout(p=0.0, inplace=False)
# )
# (output): ViTSelfOutput(
# (dense): Linear(in_features=768, out_features=768, bias=True)
# (dropout): Dropout(p=0.0, inplace=False)
# )
# )
# (intermediate): ViTIntermediate(
# (dense): Linear(in_features=768, out_features=3072, bias=True)
# (intermediate_act_fn): GELUActivation()
# )
# (output): ViTOutput(
# (dense): Linear(in_features=3072, out_features=768, bias=True)
# (dropout): Dropout(p=0.0, inplace=False)
# )
# (layernorm_before): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
# (layernorm_after): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
# )
# )
# )
# (layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
# )
# (classifier): Linear(in_features=768, out_features=8, bias=True)
# )
Hazırladığınız modelin konfigurasyonuna da kolaylıkla erişebilirsiniz:
model.config
# ViTConfig {
# "_name_or_path": "google/vit-base-patch16-224-in21k",
# "architectures": [
# "ViTModel"
# ],
# "attention_probs_dropout_prob": 0.0,
# "encoder_stride": 16,
# "hidden_act": "gelu",
# "hidden_dropout_prob": 0.0,
# "hidden_size": 768,
# "id2label": {
# "0": "dyed-lifted-polyps",
# "1": "dyed-resection-margins",
# "2": "esophagitis",
# "3": "normal-cecum",
# "4": "normal-pylorus",
# "5": "normal-z-line",
# "6": "polyps",
# "7": "ulcerative-colitis"
# },
# "image_size": 224,
# "initializer_range": 0.02,
# "intermediate_size": 3072,
# "label2id": {
# "dyed-lifted-polyps": "0",
# "dyed-resection-margins": "1",
# "esophagitis": "2",
# "normal-cecum": "3",
# "normal-pylorus": "4",
# "normal-z-line": "5",
# "polyps": "6",
# "ulcerative-colitis": "7"
# },
# "layer_norm_eps": 1e-12,
# "model_type": "vit",
# "num_attention_heads": 12,
# "num_channels": 3,
# "num_hidden_layers": 12,
# "patch_size": 16,
# "qkv_bias": true,
# "transformers_version": "4.34.0"
# }
Artık ince-ayar çekmeye hazırız!
Modele İnce-Ayar Çekme
HuggingFace’in Trainer fonksiyonunu (https://huggingface.co/docs/transformers/v4.34.0/en/main_classes/trainer#transformers.Trainer) kullanarak ince-ayar çekeceğiz. Trainer, transformer modelleri için PyTorch’ta implement edilmiş, soyutlaştırılmış bir eğitim ve değerlendirme döngüsüdür.
Ancak modeli eğitmeye geçmeden önce gerçekleştirmemiz gereken bir kaç işlem daha vardır.
Değerlendirme Metriklerini Belirleme
İlk olarak modeli değerlendirirken kullanacağımız metrikleri (ölçütleri) tanımlamamız gerekmektedir. Bu metrikleri Hugging Face’in evaluate modülünden kolaylıkla yükleyebilirsiniz - https://huggingface.co/docs/evaluate/index
evaluate modülü 100’den fazla değerlendirme metriği içermektedir:
import evaluate
# Değerlendir metriklerinin sayısı
print(f"Hugging Face'te {len(evaluate.list_evaluation_modules())} adet değerlendirme metriği vardır.\n")
# Hugging Face'te 141 adet değerlendirme metriği vardır.
Bu metriklerin ne olduğu şu şekilde görülebilir:
# Tüm değerlendirme metriklerini listele
evaluate.list_evaluation_modules()
# ['precision',
# 'code_eval',
# 'roc_auc',
# 'cuad',
# 'xnli',
# 'rouge',
# 'pearsonr'
# ...
# 'ybelkada/toxicity',
# 'ronaldahmed/ccl_win',
# 'meg/perplexity',
# 'cakiki/tokens_per_byte',
# 'lsy641/distinct']
Bu tutorial kapsamında Doğruluk (Accuracy), F1 Skoru (F1 Score) Kesinlik (Precision) ve Duyarlılık (Recall) metriklerini kullanacağız. Bu metrikleri model eğitimi esnasında kullanabilmek için, önce evaluate kütüphanesindeki load fonksiyonunu kullanarak bu metrikleri yüklemeli (load) ve daha sonra yine evaluate kütüphanesindeki compute fonksiyonu ile hesaplamaları gerçekleştirmek üzere özel bir fonksiyon yaratmalıyız:
accuracy_metric = evaluate.load("accuracy")
f1_metric = evaluate.load("f1")
precision_metric = evaluate.load("precision")
recall_metric = evaluate.load("recall")
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis = -1)
results = {}
results.update(accuracy_metric.compute(predictions=preds, references = labels))
results.update(f1_metric.compute(predictions=preds, references = labels, average="weighted"))
results.update(precision_metric.compute(predictions=preds, references = labels, average="weighted"))
results.update(recall_metric.compute(predictions=preds, references = labels, average="weighted"))
return results
Dikkat edilirse, compute fonksiyonu tahminleri (predictions) ve etiketleri (labels) beklemektedir.
Eğitim Argümanlarını belirleme
Yapmamız gereken diğer bir işlem, Eğiticinin (Trainer‘ın) ihtiyaç duyduğu argümanları tanımladığımız TrainingArguments isimli konfigürasyonları yazmaktır. Hugging Face’in transformers kütüphanesi eğitim argümanları olarak bir çok opsiyon sunmaktadır. Uygun olanları alıp, eğitim esnasında tercih edeceğiniz değerleri atayabilirsiniz - https://huggingface.co/docs/transformers/v4.34.0/en/main_classes/trainer#transformers.TrainingArguments
Bu konfigürasyonlar, eğitim parametrelerini (training parameters), kaydetme ayarlarını (saving settings) ve günlüğe kaydetme ayarlarını (logging settings) içerir:
# Modelin kaydedileceği dizin
model_dir = "./model"
# Modelin log'larının kaydedileceği dizin
output_data_dir = "./outputs"
# Eğitim için gerçekleştirilecek toplam epoch sayısı
num_train_epochs = 5
# Eğitim için GPU/TPU çekirdeği/CPU başına yığın büyüklüğü (batch size)
per_device_train_batch_size = 16
# Değerlendirme için GPU/TPU çekirdeği/CPU başına yığın büyüklüğü (batch size)
per_device_eval_batch_size = 32
# AdamW optimize edici için başlangıç öğrenme oranı
learning_rate = 2e-5
# 0'dan öğrenme_oranına (learning_rate) kadar doğrusal bir ısınma için kullanılan adım sayısı
warmup_steps = 500
# AdamW optimize edicideki tüm yan parametreleri ve LayerNorm ağırlıkları hariç tüm katmanlara uygulanacak ağırlık azalması (weight decay)
weight_decay = 0.01
# En iyi modeli seçmek için doğruluk oranını kullanalım
main_metric_for_evaluation = "accuracy"
training_args = TrainingArguments(
output_dir = model_dir,
num_train_epochs = num_train_epochs,
per_device_train_batch_size = per_device_train_batch_size,
per_device_eval_batch_size = per_device_eval_batch_size,
warmup_steps = warmup_steps,
weight_decay = weight_decay,
evaluation_strategy="epoch",
save_strategy = "epoch",
logging_strategy = "epoch",
logging_dir = f"{output_data_dir}/logs",
learning_rate = float(learning_rate),
load_best_model_at_end = True,
remove_unused_columns=False,
push_to_hub=False,
metric_for_best_model = main_metric_for_evaluation)
Ek, olarak Google Colab üzerinde GPU ile çalıştığımızdan, aşağıdaki gibi tanımlama gerçekleştirdikten sonra model operasyonlarını GPU üzerine yerleştirebiliriz:
# device, model eğitiminin GPU veya CPU üzerinde gerçekleşip gerçekleşmeyeceğine karar verecek
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# device(type='cuda')
model.to(device)
Daha sonra, eğitim görüntülerini yığın büyüklüğü (batch size) kadar yığınlayacak bir collate (türkçesi harmanlama’dır) fonksiyonu yazmanız gerekmektedir. collate fonksiyonu çok sayıda veriyle uğraşırken kullanışlıdır. Modele besleyeceğimiz görüntülerden oluşan yığınlar (batches), sözlüklerden oluşan listelerdir, dolayısıyla collate yığınlaştırılmış tensörler oluşturmamıza yardımcı olacaktır.
def collate_fn(batch):
return {
'pixel_values': torch.tensor([x['pixel_values'] for x in batch]),
'labels': torch.tensor([x['label'] for x in batch])
}
Artık hazırız! Şimdi bir Trainer örneği (instance) yaratalım:
trainer = Trainer(
model=model,
args=training_args,
data_collator=collate_fn,
compute_metrics=compute_metrics,
train_dataset=prepared_train,
eval_dataset=prepared_test,
tokenizer=feature_extractor,
)
Burada, elimizdeki modeli, oluşturduğumuz eğitim argümanlarını, collate fonksiyonunu, ön-işlemeden geçirilmiş eğitim ve test kümelerini ve modele ait öznitelik çıkarıcıyı (feature extractor) kullanırız.
…ve modeli eğitmeye hazırız:
trainer.train()

Modelin 5 epoch boyunca eğitilmesi neredeyse 1 saat 51 dakika sürmüştür. Eğitim sonunda, ince-ayar çekilmiş modelin test kümesi üzerindeki performansını yukarıdaki ekran görüntüsünde görebilirsiniz. Oldukça iyi bir sonuç! :)
Malesef ki, Hugging Face’in transformers kütüphanesi eğitim kümesi üzerinde her epoch için değerlendirme metriklerini ölçmemektedir. Bunu gerçekleştirmek için, özel bir Geri Çağırma (Callback) fonksiyonu yazabilirsiniz.
Model eğitim sonuçlarını aşağıdaki şekilde elde edebilirsiniz:
log_history = pd.DataFrame(trainer.state.log_history)
log_history = log_history.fillna(0)
log_history = log_history.groupby(['epoch']).sum()
log_history

Eğitim kümesi üzerindeki kaybı, test kümesi üzerindeki kaybı ve test kümesi üzerindeki doğruluk oranını her epoch için şu şekilde kolaylıkla görsel olarak inceleyebilirsiniz:
log_history[["loss", "eval_loss", "eval_accuracy"]].plot(subplots=True)

Hugging Face eğitim kümesine (training dataset) ait değerlendirme metriklerini döndürmediği için, en son elde edilen modeli tüm eğitim kümesi üzerinde çalıştırarak tanımladığımız metriklerin değerlerini evaluate fonksiyonu ile elde edebiliriz:
metrics_training = trainer.evaluate(prepared_train)
metrics_training
# {'eval_loss': 0.09327180683612823,
# 'eval_accuracy': 0.9905882352941177,
# 'eval_f1': 0.990587445420025,
# 'eval_precision': 0.9906179579903401,
# 'eval_recall': 0.9905882352941177,
# 'eval_runtime': 992.092,
# 'eval_samples_per_second': 6.854,
# 'eval_steps_per_second': 0.215,
# 'epoch': 5.0}
EK NOT
Eğitim kümesine ait metrikleri elde etmek için diğer bir yöntem predict methodunu kullanmaktır. Böylelikle, model tahminlerini alır ve bu tahminleri gerçek etiketlerle karşılaştırabiliriz.
# Eğitim kümesi üzerinde yapılan tahminler
y_train_predict = trainer.predict(prepared_train)
# Tahminlere göz atalım
y_train_predict
Transfer öğrenme görüntü sınıflandırma modeli için tahmin edilen lojitler, predictions metodu kullanılarak çıkarılabilir:
# Tahmin edilen lojitler
y_train_logits = y_train_predict.predictions
# İlk 5 görüntüye ait model çıktıları (lojitler)
y_train_logits[:5]
Tek bir görüntü için elde edilen tahminin sekiz sütundan oluştuğunu görüyoruz. İlk sütun, etiket 0 için tahmin edilen lojittir ve ikinci sütun, etiket 1 için tahmin edilen lojittir ve bu böyle devam etmektedir. Lojit değerlerinin toplamı 1’e eşit değildir çünkü bu değerler normalleştirilmemiş olasılıklardır (diğer bir deyişle, model çıktısıdır). Çok-sınıflı sınıflandırma (multi-class classification) yaptığımız için Softmax fonksiyonu kullanarak bu değerleri normalleştirebiliriz:
y_train_probabilities = torch.softmax(y_train_logits, dim = -1)
Softmax’ı uyguladıktan sonra, her görüntü için tahmin edilen olasılığın toplamının 1’e eşit olduğunu görebiliriz:
# İlk 5 görüntüye ait normalleştirilmiş olasılıklar
y_train_probabilities[:5]
Tahmin edilen etiketleri elde etmek için, her görüntü için etiketlere karşılık gelen maksimum olasılık indeksini döndürmek üzere numpy kütüphanesinin argmax fonksiyonu kullanılır.
# model tarafından eğitim kümesi üzerinde tahmin edilen etiketler
y_train_pred_labels = np.argmax(y_train_probabilities, axis=1)
# İlk 5 görüntüye ait tahmin edilen etiketler
y_train_pred_labels[:5]
Gerçek etiketler y_train_predict.label_ids kullanılarak çıkarılabilir.
# Asıl Etiketler
y_train_actual_labels = y_train_predict.label_ids
# Eğitim kümesindeki ilk 5 görüntüye ait gerçek etiketler
y_train_actual_labels[:5]
Artık gerçek etiketleri (actual labels), eğitim kümesi üzerinde model tarafından tahmin edilen etiketler ile karşılaştırabiliriz.
Daha fazla model performans metriği hesaplamak için ilgilenilen metrikleri yüklemek amacıyla evaluate.load‘u kullanabiliriz. Bazı metrikleri zaten yukarıdaki hücrelerin birinde yüklemiştik:
# Compute accuracy metric
print(accuracy_metric.compute(predictions=y_train_pred_labels, references=y_train_actual_labels))
# Compute f1 metric
print(f1_metric.compute(predictions=y_train_pred_labels, references=y_train_actual_labels, average="weighted"))
# Compute precision metric
print(precision_metric.compute(predictions=y_train_pred_labels, references=y_train_actual_labels, average="weighted"))
# Compute recall metric
print(recall_metric.compute(predictions=y_train_pred_labels, references=y_train_actual_labels, average="weighted"))
En İyi Modeli Kaydetme
Artık sonuçlarımızdan memnun olduğumuza göre en iyi modeli kaydedebiliriz.
trainer.save_model(model_dir)
Yukarıdaki kod satırı hem modeli hem de modelle kullanılan öznitelik çıkarıcıyı (feature extractor) model dizinine kayıt edecektir.
Ancak, sadece öznitelik çıkarıcıyı kaydetmek isterseniz feature_extractor.save_pretrained(model_dir) kodunu kullanabilirsiniz. Bu kod sadece preprocessor_config.json dosyasını model_dir isimli dizine kaydedecektir.
Sonunda ince ayar çekilmiş ViT modeline sahibiz! 🥳🥳🥳 🎉🎉🎉
Modeli Test Kümesi Üzerinde Değerlendirme
Yukarıdaki adımlara benzer şekilde şimdi test kümesindeki performansını doğrulamamız ve değerlendirme sonuçlarını (evaluation results) kaydetmemiz gerekmektedir.
metrics = trainer.evaluate(prepared_test)
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)

save_metrics fonksiyonu test kümesi üzerinde değerlendirilen modelin sonuçlarını model_dir dizininin (bizim örneğimizde ./model klasörü) altında eval_results.json olarak kaydedecektir.
Elde ettiğimiz modelin doğruluğu oldukça iyi.
İhtiyaç halinde test kümesinin ince-ayar çekilmiş model tarafından tahmin edilen etiketleri de elde edilebilir:
y_test_predict = trainer.predict(prepared_test)
y_test_predict
# PredictionOutput(predictions=array([[-0.5574911 , -0.55256057, -0.44084704, ..., -0.6514604 ,
# -0.587717 , 4.1993985 ],
# [ 4.004751 , -0.9422177 , -0.65568745, ..., -0.59566027,
# -0.17343669, -0.4465061 ],
# [-0.87891173, -1.0014176 , 2.749767 , ..., 2.7222385 ,
# -1.0784245 , -0.91497976],
# ...,
# [-0.6408027 , -0.6666713 , -0.70249856, ..., -0.46141627,
# -0.4458719 , -0.84069437],
# [-0.6629647 , -0.72915053, -0.6185216 , ..., -0.6192481 ,
# -0.17926458, -0.71570873],
# [-0.6530872 , -0.67923456, -0.50120807, ..., -0.61496264,
# -0.73776233, -0.31934953]], dtype=float32), label_ids=array([7, 0, 5, ..., 4, 3, 3]), metrics={'test_loss': 0.23830144107341766, 'test_accuracy': 0.9391666666666667, 'test_f1': 0.9390956371766551, 'test_precision': 0.939918876802155, 'test_recall': 0.9391666666666667, 'test_runtime': 313.2723, 'test_samples_per_second': 3.831, 'test_steps_per_second': 0.121})
Transfer öğrenme görüntü sınıflandırma modeli için tahmin edilen lojitler, predictions metodu kullanılarak çıkarılabilir:
# Tahmin edilen lojitler
y_test_logits = y_test_predict.predictions
# İlk 5 görüntüye ait model çıktıları (lojitler)
y_test_logits[:5]
# array([[-0.5574911 , -0.55256057, -0.44084704, -0.43077588, -0.69217765,
# -0.6514604 , -0.587717 , 4.1993985 ],
# [ 4.004751 , -0.9422177 , -0.65568745, -0.64027154, -0.7201288 ,
# -0.59566027, -0.17343669, -0.4465061 ],
# [-0.87891173, -1.0014176 , 2.749767 , -0.8135734 , -1.0272567 ,
# 2.7222385 , -1.0784245 , -0.91497976],
# [-0.44040072, -0.60538346, -0.6533643 , -0.5478527 , -0.48782963,
# -0.50029 , 4.1607065 , -0.6397783 ],
# [-0.66559803, -0.6086572 , -0.5033142 , -0.36208436, -0.53697765,
# -0.7260709 , -0.3696426 , 4.2133403 ]], dtype=float32)
Tek bir görüntü için elde edilen tahminin sekiz sütundan oluştuğunu görüyoruz. İlk sütun, etiket 0 için tahmin edilen lojittir ve ikinci sütun, etiket 1 için tahmin edilen lojittir ve bu böyle devam etmektedir. Lojit değerlerinin toplamı 1’e eşit değildir çünkü bu değerler normalleştirilmemiş olasılıklardır (diğer bir deyişle, model çıktısıdır). Çok-sınıflı sınıflandırma (multi-class classification) yaptığımız için Softmax fonksiyonunu kullanarak bu değerleri normalleştirebiliriz:
y_test_probabilities = torch.softmax(torch.tensor(y_test_logits), dim = 1)
Softmax’ı uyguladıktan sonra, her görüntü için tahmin edilen olasılıkların toplamının 1’e eşit olduğunu görebiliriz:
# İlk 5 görüntüye ait normalleştirilmiş olasılıklar
y_test_probabilities[:5]
# tensor([[0.0081, 0.0081, 0.0091, 0.0092, 0.0071, 0.0074, 0.0079, 0.9431],
# [0.9328, 0.0066, 0.0088, 0.0090, 0.0083, 0.0094, 0.0143, 0.0109],
# [0.0125, 0.0111, 0.4714, 0.0134, 0.0108, 0.4586, 0.0103, 0.0121],
# [0.0094, 0.0080, 0.0076, 0.0085, 0.0090, 0.0089, 0.9408, 0.0077],
# [0.0072, 0.0076, 0.0084, 0.0097, 0.0082, 0.0067, 0.0096, 0.9426]])
Tahmin edilen etiketleri elde etmek için, her görüntü için etiketlere karşılık gelen maksimum olasılığa sahip indeksi döndürmek üzere NumPy kütüphanesinin argmax fonksiyonu kullanılır:
# model tarafından eğitim kümesi üzerinde tahmin edilen etiketler
y_test_pred_labels = np.argmax(y_test_probabilities, axis=1)
# İlk 5 görüntüye ait tahmin edilen etiketler
y_test_pred_labels[:5]
# tensor([7, 0, 2, 6, 7])
Gerçek etiketler y_test_predict.label_ids kullanılarak çıkarılabilir.
# Asıl Etiketler
y_test_actual_labels = y_test_predict.label_ids
# Eğitim kümesindeki ilk 5 görüntüye ait gerçek etiketler
y_test_actual_labels[:5]
# array([7, 0, 5, 6, 7])
Artık gerçek etiketleri (actual labels), eğitim kümesi üzerinde model tarafından tahmin edilen etiketler ile karşılaştırabiliriz.
Daha fazla model performans metriği hesaplamak için ilgilenilen metrikleri yüklemek amacıyla evaluate.load‘u kullanabiliriz. Bazı metrikleri zaten yukarıdaki hücrelerin birinde yüklemiştik:
# Compute accuracy metric
print(accuracy_metric.compute(predictions=y_test_pred_labels, references=y_test_actual_labels))
# Compute f1 metric
print(f1_metric.compute(predictions=y_test_pred_labels, references=y_test_actual_labels, average="weighted"))
# Compute precision metric
print(precision_metric.compute(predictions=y_test_pred_labels, references=y_test_actual_labels, average="weighted"))
# Compute recall metric
print(recall_metric.compute(predictions=y_test_pred_labels, references=y_test_actual_labels, average="weighted"))
# {'accuracy': 0.9391666666666667}
# {'f1': 0.9390956371766551}
# {'precision': 0.939918876802155}
# {'recall': 0.9391666666666667}
Kolaylıkla anlaşılacağı üzere elde edilen sonuçlar, trainer.evaluate(prepared_test) kod satırının döndürdüğü sonuçlar ile aynıdır!
Tek Bir Görüntü Üzerinde Modelin Tahmini
Şimdi de rastgele bir görüntünün sınıf tahmini (class prediction) elde edelim. Test veri kümemizdeki bir görseli seçip tahmin edilen etiketin doğru olup olmadığını görebiliriz.
image = test_dataset["image"][0]
image

Bu görüntüye ait asıl etiketi (actual label) bulalım:
# extract the actual label of the first image of the testing dataset
actual_label = id2label[str(test_dataset["label"][0])]
actual_label
# 'ulcerative-colitis'
Görüntünün bir ulcerative-colitis sınıfına ait olduğunu görüyoruz. Şimdi modelimizin ne tahmin ettiğini görelim.
Bunun için modelimizi bir daha yüklüyoruz:
model_finetuned = ViTForImageClassification.from_pretrained(model_dir)
feature_extractor_finetuned = ViTFeatureExtractor.from_pretrained(model_dir)
Daha sonra orijinal test görüntüsünü eğittiğimiz modele ait öznitelik çıkarıcıdan (feature extractor) geçiriyoruz ve elde edilen tensörü modelimize besliyoruz.
Burada no_grad, yalnızca çıkarsama (inference) yaptığımız için gradyan hesaplamasını devre dışı bırakan bir bağlam yöneticisidir (context manager).
inputs = feature_extractor_finetuned(image, return_tensors="pt")
with torch.no_grad():
logits = model_finetuned(**inputs).logits
logits
# tensor([[-0.5575, -0.5526, -0.4408, -0.4308, -0.6922, -0.6515, -0.5877, 4.1994]])
Elde edilen tensor her 8 sınıfa ait lojit değerleridir.
Lojitler üzerinde NumPy kütüphanesinin argmax fonksiyonunu çağırdığımızda, en yüksek olasılığa sahip sınıfın indeksini alırsınız:
predicted_label = logits.argmax(-1).item()
predicted_label
# 7
predicted_class = id2label[str(predicted_label)]
predicted_class
# 'ulcerative-colitis'
İnce ayar çekilmiş modelin tahmini de ulcerative-colitis! Tam da beklediğimiz gibi!
İnce Ayar Çekilmiş Modeli Hugging Face Hub’a Push’lamak
Modelimizin değerlendirme aşamasını da tamamladıktan sonra başkaları tarafından kullanılmak üzere Hugging Face’in Hub’ına push’layabiliriz!
notebook_login()
` notebook_login()` fonksiyonunu çalıştırdıktan sonra sizden bir token oluşturmanızı ve bu oluşturduğunuz token’ı ekrana girmenizi isteyecektir:
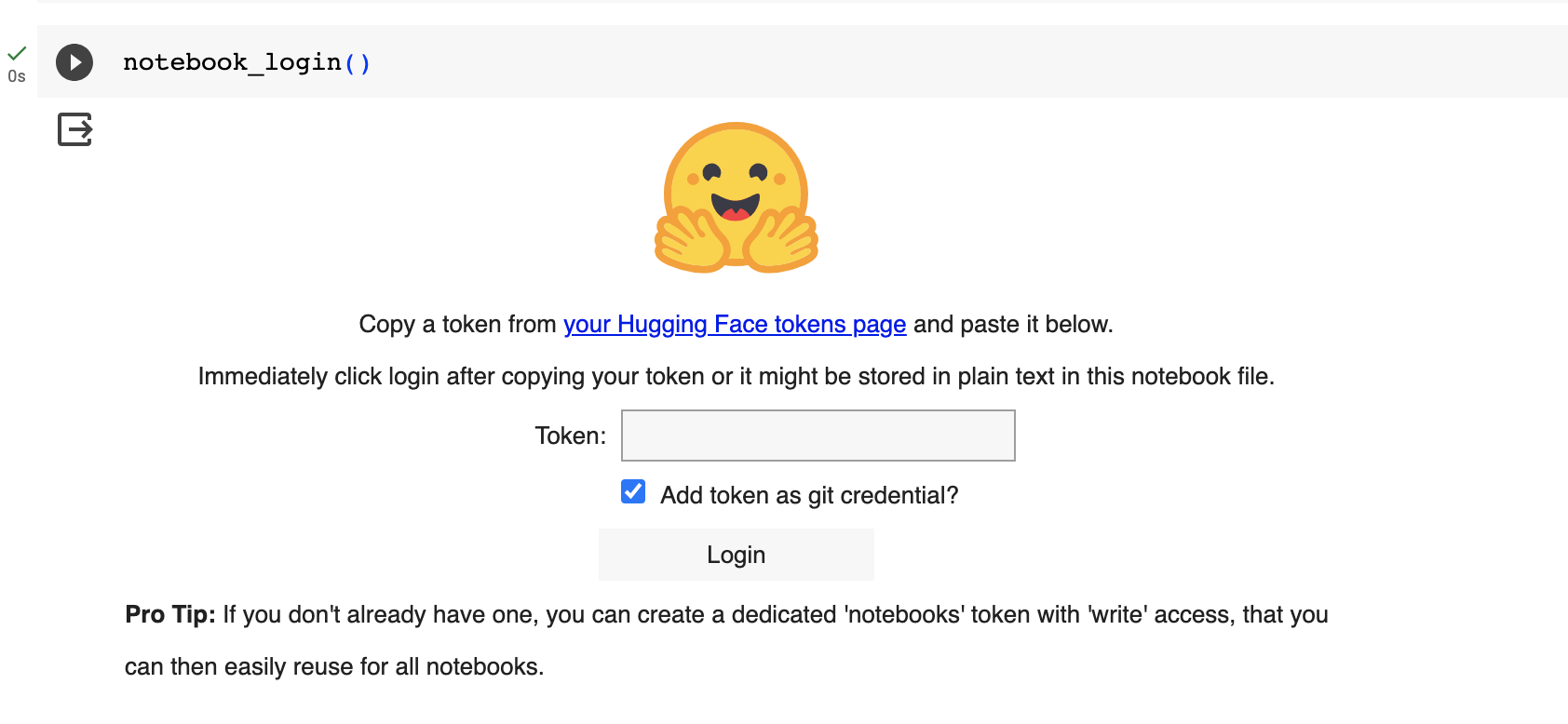
Token oluşturmak için https://huggingface.co/settings/tokens sayfasına gidiniz, New Token butonuna tıklayınız. Token ismini (Name) giriniz. Role olarak da write seçmeyi unutmayınız. Çünkü daha sonra Hugging Face Hub’da bir repo oluşturacağız ve bu repoya dosyaları ekleyebilmek için yazma izinlerine (write permissions) sahip olmamız gerekmektedir:

Token’ı ilgili boşluğa girip Login butonuna bastığınız zaman Login successful çıktısını aldığınızdan emin olunuz:

Notebook üzerinden Hugging Face ortamına giriş yaptıktan sonra, ilk olarak Hub’da bir depo (respository) oluşturmamız gerekmektedir. create_repo fonksiyonuna kullanıcı adınızı ve oluşturacağınız deponun ismini girmeniz istenir:
create_repo("mmuratarat/kvasir-v2-classifier", private=False)
# RepoUrl('https://huggingface.co/mmuratarat/kvasir-v2-classifier', endpoint='https://huggingface.co', repo_type='model', repo_id='mmuratarat/kvasir-v2-classifier')
Depoyu oluşturduktan sonra artık Kvasir veri kümesi için ince ayar çektiğimiz Visual Transformer modelini Hub’a gönderebiliriz (push’layabiliriz):
model_finetuned.push_to_hub("mmuratarat/kvasir-v2-classifier")
feature_extractor_finetuned.push_to_hub("mmuratarat/kvasir-v2-classifier")
Artık modelimizi herkes kolaylıkla kullanabilir.
Modelin sayfasına https://huggingface.co/mmuratarat/kvasir-v2-classifier bağlantısından ulaşabilirsiniz.
NOT: Bu yöntem otomatik olarak bir model kartı yaratmaz. Bu nedenle, başkalarının sizin çalışmanızı kolay anlaması için bir model kartı yaratmayı unutmayınız!
Hugging Face’in Auto Sınıflarını Kullanarak Hub’daki İnce Ayar Çekilmiş Modele Erişmek
Artık Hugging Face’in Auto sınıflarını kullanabiliriz - https://huggingface.co/docs/transformers/v4.33.3/en/model_doc/auto#auto-classes
Çoğu durumda kullanmak istediğiniz mimari, from_pretrained() metoduna sağladığınız önceden eğitilmiş modelin adından (name) veya yolundan (path) tahmin edilebilir.
Auto sınflar bu işi sizin için yapmak için buradalar; böylelikle, adı/yolu verilen önceden-eğitilmiş (pre-trained) ilgili modeli ve bu modelin önceden-eğitilmiş ağırlıklarını (weights), konfigürasyonlarını (config) ve kelime hazinesini (vocabuları) otomatik olarak alırsınız.
AutoModelForImageClassification sınıfı ile elde ettiğimiz modeli Hub’dan istediğimiz zaman çekerek çıkarsamalar yapabilirsiniz. Ancak girdi görüntülerini önce bir öznitelik çıkarıcıdan geçirmemiz gerekmektedir. Bunu ise AutoFeatureExtractor sınıfı ile gerçekleştirebilirsiniz. Sonuçta eğittiğimiz modelde kullanılan öznitelik çıkarıcı (feature extractor) model ile birlikte preprocessor_config.json isimli bir JSON dosyasına kaydedildi ve Hub’a gönderildi.
Buraya not düşülmesi gereken bir başka konu ise, modeli eğitirken kullanılan argümanların da bir JSON dosyası olarak kaydedildiğidir. Bu dosya bir konfigurasyon dosyasıdır ve config.json ismiyle bir JSON dosyası şeklinde model dizinin altına kaydedilmiş ve Hub’a gönderilmiştir.
model = AutoModelForImageClassification.from_pretrained("mmuratarat/kvasir-v2-classifier")
feature_extractor = AutoFeatureExtractor.from_pretrained("mmuratarat/kvasir-v2-classifier")
Test kümesindeki 582. görüntüyü alalım:
image = test_dataset["image"][582]
actual_label = id2label[str(test_dataset["label"][582])]
actual_label
# 'normal-z-line'
Bu görüntünün gerçek sınıfı normal-z-line‘dır.
Şimdi indirdiğimiz modelin tahminin elde edelim:
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
predicted_label = logits.argmax(-1).item()
predicted_class = id2label[str(predicted_label)]
predicted_class
# 'normal-z-line'
Doğru cevap!
Inference API’sını Kullanarak Görüntünün Sınıf Tahmini
Bilgisayarınızda yerel olarak bir görüntünün sınıfını nasıl tahmin edebileceğinizi yukarıda gördük. Buna ek olarak, Hugging Face’in sağladığı bir kolaylık olan Inference API’sını da kullanabilirsiniz. Tarayıcınız (browser) üzerinden gastrointestinal sistemin içerisinden alınan istediğiniz bir görüntünün tahmini elde edebilirsiniz:
Tek yapmanız gereken bilgisayarınızdan görüntüyü upload etmek. Şimdi polyps sınıfından bir görüntüyü (görüntüyü buradan indirebilirsiniz) buraya gönderelim:
{kind=link}
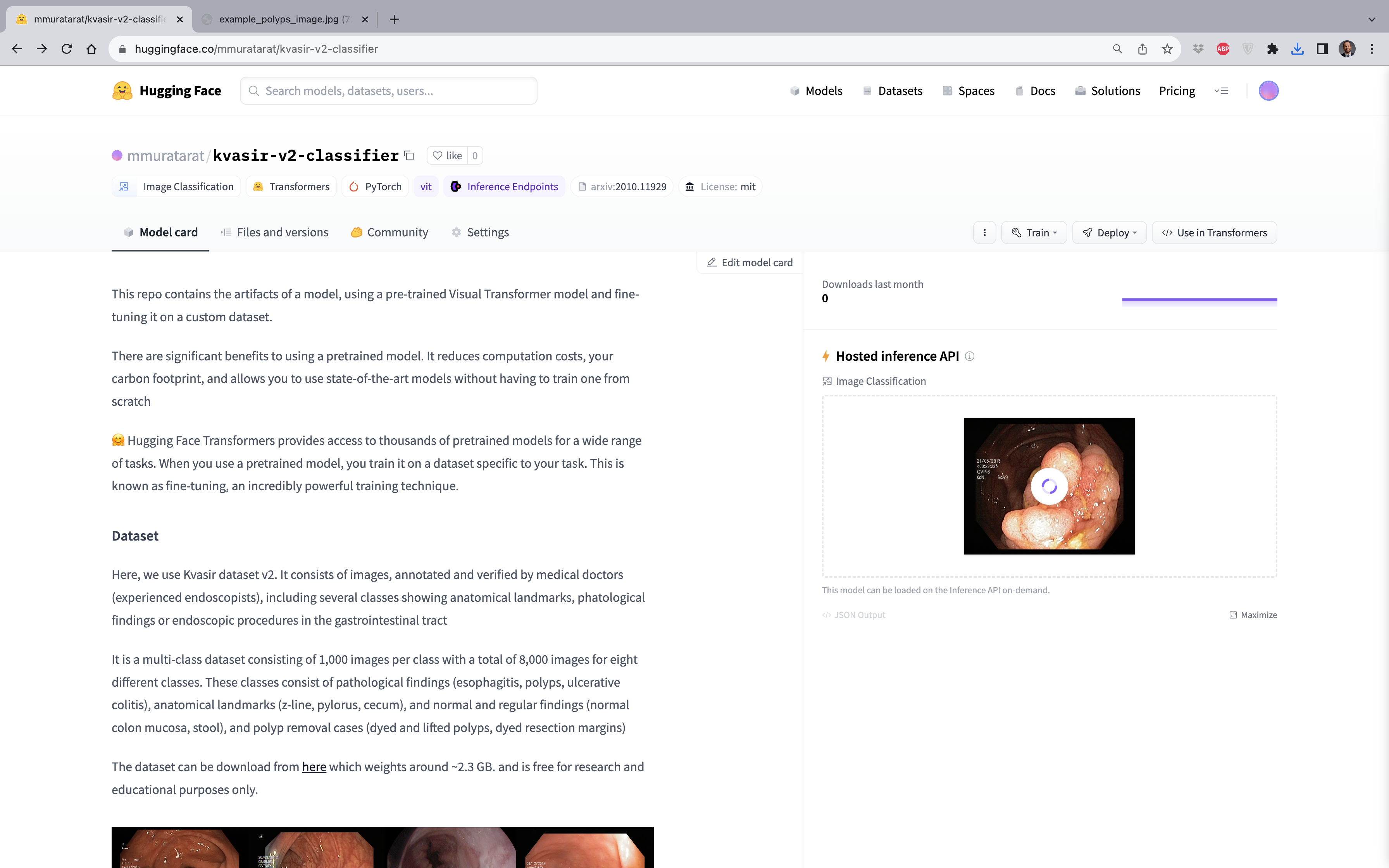


Kolaylıkla anlaşılacağı üzere, model, %94.1 olasılıkla bu görüntünün polyps sınıfına ait olduğunu doğru bir şekilde tahmin etmiştir!