on
7 mins to read.
Columnar Storage
An important part of the Hadoop ecosystem is HDFS, Hadoop’s distributed file system. Like other file systems the format of the files you can store on HDFS is entirely up to you. A storage format is just a way to define how information is stored in a file. When dealing with Hadoop’s filesystem not only do you have all of these traditional storage formats available to you (like you can store PNG and JPG images on HDFS if you like), but you also have some Hadoop-focused file formats to use for structured and unstructured data. Some common storage formats for Hadoop include:
- Plain text storage (eg, CSV, TSV files - row-based file format)
- Sequence Files
- Apache Avro (row-based file format)
- Apache Parquet (column-based file format)
- Apache ORC (column-based file format)
The textbook definition is that columnar file formats store data by column, not by row. CSV, TSV, JSON, and Avro, are traditional row-based file formats. Parquet, and ORC file are columnar file formats.
Apache Parquet and Apache ORC formats are both open-source and are currently supported by multiple proprietary and open-source Big Data frameworks.
For example, the Parquet file format can be illustrated as:

and the structure of ORC file format is shown below:

In order to understand the difference between row-based and column-based data storage format, these two illustrations might be very helpful.
Imagine the data values from the four columns of a table represented as different colored boxes:
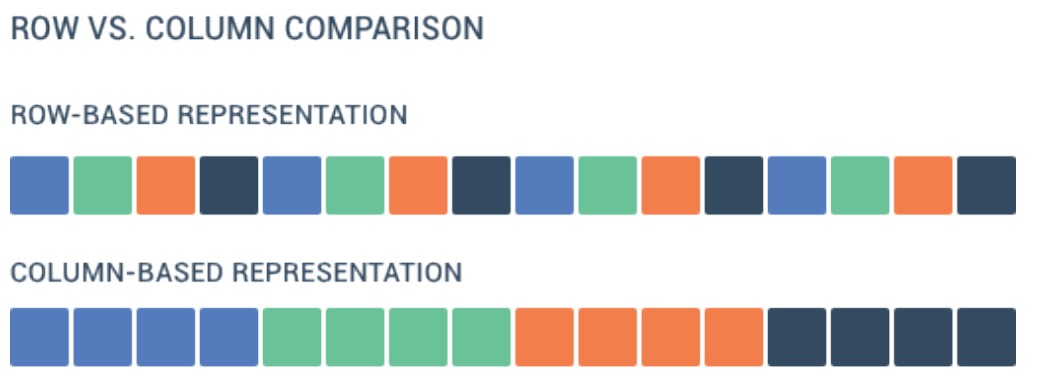
and another example when we have 5 different variables in the table:

Let’s get into the details…
Row-Oriented Database
Traditional databases store data by each row and the fields for each record are sequentially stored.
Let’s say you have a table like this:
+----+--------------+----------------------+----------+-------------+------------+-----------+-----+
| ID | name | address | zip code | phone | city | country | age |
+----+--------------+----------------------+----------+-------------+------------+-----------+-----+
| 1 | Benny Smith | 23 Workhaven Lane | 52683 | 14033335568 | Lethbridge | Canada | 43 |
| 2 | Keith Page | 1411 Lillydale Drive | 18529 | 16172235589 | Woodridge | Australia | 26 |
| 3 | John Doe | 1936 Paper Blvd. | 92512 | 14082384788 | Santa Clara| USA | 33 |
+----+--------------+----------------------+----------+-------------+------------+-----------+-----+
To process this two-dimensional table, a computer would read this data from left to right, starting at the first row and then reading each subsequent row:
1,Benny Smith,23 Workhaven Lane,52683,14033335568,Lethbridge,Canada,43;2,Keith Page,1411 Lillydale Drive,18529,16172235589,Woodridge,Australia,26;3,John Doe,1936 Paper Blvd.,92512,14082384788,Santa Clara,USA,33;
As you can see, a record’s fields are stored one by one, then the next record’s fields are stored, then the next, and on and on. This shows how records from database tables are typically stored into disk blocks by row. A disk block is basically one row in the database. In other words 1,Benny Smith,23 Workhaven Lane,52683,14033335568,Lethbridge,Canada,43 is one disk block, 2,Keith Page,1411 Lillydale Drive,18529,16172235589,Woodridge,Australia,26 is the second block and 3,John Doe,1936 Paper Blvd.,92512,14082384788,Santa Clara,USA,33 is the third one and so on…
In a typical relational database table, each row contains field values for a single record. In row-wise database storage, data blocks store values sequentially for each consecutive column making up the entire row. If block size is smaller than the size of a record, storage for an entire record may take more than one block. If block size is larger than the size of a record, storage for an entire record may take less than one block, resulting in an inefficient use of disk space. In online transaction processing (OLTP) applications, most transactions involve frequently reading and writing all of the values for entire records, typically one record or a small number of records at a time. As a result, row-wise storage is optimal for OLTP databases.
Traditional databases are row oriented databases that store data by row. Common row oriented databases are PostgreSQL and MySQL. Row oriented databases are still commonly used for Online Transactional Processing (OLTP) style applications.
Column-oriented Database
In columnar formats, data is stored sequentially by column, from top to bottom—not by row, left to right:
1,2,3;Benny Smith,Keith Page,John Doe;23 Workhaven Lane,1411 Lillydale Drive,1936 Paper Blvd.;52683,18529,92512;14033335578,16172235589,14082384788;Lethbridge,Woodridge,Santa Clara;Canada,Australia,USA;43,26,33;
Each field is stored by the column so that each id is stored, then the name column, then the address, etc. Using columnar storage, each data block stores values of a single column for multiple rows.
The primary benefit is that some of your queries could become really fast. Having data grouped by column makes it more efficient to easily focus computation on specific columns of data. Reading only relevant columns of data saves compute costs as irrelevant columns are ignored. Having the data stored sequentially by column allows for faster scan of the data because all relevant values are stored next to each other. There is no need to search for values within the rows. Imagine, for example, that you wanted to know the average age of all of your users. Instead of looking up the age for each record row by row (row-oriented database), you can simply jump to the area where the age data is stored and read just the data you need. So when querying, columnar storage lets you skip over all the non-relevant data very quickly. Hence, aggregation queries (queries where you only need to lookup subsets of your total data) could become really fast compared to row-oriented databases.
Another added advantage is that each block holds the same type of data (they keep homogenous data in a single block), block data can use a compression scheme selected specifically for the column data type, further drastically reducing the overall disk I/O requirements and the amount of data you need to load from disk space.
The savings in space for storing data on disk also carries over to retrieving and then storing that data in memory. Since many database operations only need to access or operate on one or a small number of columns at a time, you can save memory space by only retrieving blocks for columns you actually need for a query.
Column-based storage is also ideal for sparse data sets where you may have empty values.
Columnar databases are designed for data warehousing and big data processing because they scale using distributed clusters of low-cost hardware (a large number of machines) to increase throughput.
However, there might be many cases where you actually do need multiple fields from each row. And columnar databases are generally not great for these types of queries. That is, if there are many fields to be read, then the columnar storage is inefficient. In fact, if your queries are for looking up user-specific values only (or, all fields in a row need to be accessed), row-oriented databases usually perform those queries much faster. Writing new data could take more time in columnar storage. If you are inserting a new record into a row-oriented database, you can simply write that in one operation (just add that row at the end of the disk block). But if you are inserting a new record to a columnar database, you need to write to each column one by one. Resultantly, loading new data or updating many values in a columnar database could take much more time.
While a relational database is optimized for storing rows of data, typically for transactional applications, a columnar database is optimized for fast retrieval of columns of data, typically in analytical applications. That’s why you need to start with a row-oriented database as the back-end component of your application. Once the application becomes big, then, think about switching over to the columnar database to enable business analytics.
Common column oriented databases are Amazon Redshift, BigQuery and Snowflake. This column oriented database is being used by most major providers of cloud data warehouses.
In summary, the most important consideration when selecting a big data format is whether a row or column-based format is best suited to your objectives. At the highest level, column-based storage is most useful when performing analytics queries that require only a subset of columns examined over very large data sets. If your queries require access to all or most of the columns of each row of data, row-based storage will be better suited to your needs.
References
- https://link.springer.com/content/pdf/10.1007%2F978-3-319-63962-8_248-1.pdf
- https://thinksis.com/wp-content/uploads/2018/10/Nexla_Whitepaper_Introduction-to-Big-Data-Formats-Saket-Saurabh.pdf
- https://github.com/awsdocs/amazon-redshift-developer-guide/blob/master/doc_source/c_columnar_storage_disk_mem_mgmnt.md